Context SQL Sync
Introduction
The Context SQL Sync REST service allows importation (either one-time or by scheduling a continuous job) of context data from an SQL database (PostgreSQL, MySQL, or MS SQL) to TrendMiner.
To conduct a synchronization, the service requires two components: a datasource and a query. The datasource defines the connection to the SQL database, from which the data will be fetched. The query provides the SQL query (along with other details as explained later in this document) that will be used to select rows based on a specified time interval. The Context SQL Sync service will create a new context item in TrendMiner (or update an existing item) from each row selected by the query.
Finally, when doing a live sync, a third component is required - a sync job. The sync job encapsulates details, such as the datasource and query that should be used, and the sync frequency, etc.
The steps to sync context data are:
Request an access token for authentication
Define a datasource
Define a query
Perform a one-time sync
or
Define and execute a continuous sync job
Authentication
Prior to version 2021R2.3 only OAuth2 authentication is supported.
As of TrendMiner version 2021R2.3 OpenID Connect/OAuth2 authorization using Keycloak server is introduced. In order to be authorized to use Context SQL Sync swagger UI for service configuration, a user should authenticate and get an access token, which can be used from swagger UI. To get a token:
Open a browser and navigate to <TM-URL>/context-sql-sync/swagger-ui.html#/
Click Authorize button
In the pop-up screen, scroll to openIdConnect (OAuth2, authorization_code) flow.
Enter tm-context-sql-sync-swagger as client_id and select all scopes.
Click Authorize and then log into TrendMiner with user credentials provided.
Note
The access token has a lifespan of 5 minutes, so after that time a new token should be requested, i.e. repeat the above steps.
Context Sync API
A swagger interface is shipped with your appliance and is available on:
<TM-URL>/context-sql-sync/swagger-ui.html#/
When using the swagger interface, an authentication can be done through the browser, by logging in the Trendhub where the swagger is hosted, i.e.:
<TM-URL>
Note
When executing requests in swagger the values in the request body should not contain new lines and tabs. This is especially important when defining the SQL query (see below), because this query is usually very long.
Define a datasource
Note
See Kerberos and Integrated Authentication section, when datasource with integrated security should be used.
The datasource contains the details necessary to connect to the SQL database, such as the type of the database, the address and port, and the credentials which should be used to authenticate. New datasources can be defined by the API:
Method: POST
Path: /context-sql-sync/datasource
Authorization header: Bearer [access_token]
Body
{
"name": "localdb",
"jdbcUrl": "jdbc:postgresql://localhost:5432/tm_context_sql_sync",
"dbType": "POSTGRES",
"username": "postgres",
"password": "postgres"
}Parameter | Description |
|---|---|
name | An arbitrary string. |
jdbcUrl | A JDBC url, specifying the connection to the database. E.g.: jdbc:mysql://192.0.2.1:3306/database jdbc:postgresql://localhost:5432/database jdbc:sqlserver://localhost:1433;databaseName=database jdbc:redshift://localhost:5439/database |
dbType | Specifies the type of the database. The supported values are: MYSQL POSTGRES MSSQL REDSHIFT Contact your TrendMiner CSM in case of different databases to see how we could help out. |
username/password | The credentials used to access the database; can be omitted if the database does not require authentication. |
The result will contain the id of the newly created datasource. This id will be used later when executing a historical sync or when defining sync jobs.
Define a Query
New queries can be defined by the API:
Method: POST
Path: /context-sql-sync/query
Authorization header: Bearer [access_token]
Body
{
"name": "queryAlias",
"supportsParameters": true,
"supportsNamedParameters": true,
"componentLookupStrategy": "ASSETS|TAGS|ASSETS_THEN_TAGS",
"fieldNames": "customField1, customField2",
"validateFieldNames": true,
"timeZone": "string",
"sqlString": "Select id, componentId, type, description, start_event, start_time, stop_event, stop_time, customField1, customField2 from LOGBOOK where :startDate <= start_time and start_time < :endDate;"
"typeMapping": [
{ "PRODUCTION": "MAPPED_TYPE" },
{ "SOURCE_TYPE": "TM_TYPE" }
]
}Parameters | Description | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
name | An arbitrary string. | ||||||||||||||||||
supportsParameters | A boolean value (true|false) indicating whether the SQL query contains positional parameters. The default is true. Positional parameters are specified with question marks '?' in the SQL query. The query should contain exactly two parameters - they will be replaced with the start and end time of the requested time interval respectively. | ||||||||||||||||||
supportsNamedParameters | A boolean value (true|false) indicating whether the SQL query contains named parameters. The default is true. If this property is set to true, it will take precedence over supportsParameters. Named parameters are specified with the ':startDate' and ':endDate' (without the quotes) values in the SQL query - they will be replaced with the start and end time of the requested time interval respectively. | ||||||||||||||||||
componentLookupStrategy | A value specifying how to interpret the componentId returned by the query. The allowed values are ASSETS (componentId is interpreted as the external id of an asset), TAGS (componentId is interpreted as a tag name), and ASSETS_THEN_TAGS (componentId is interpreted as an asset and, if no asset is found, then componentId is interpreted as a tag name). The default is ASSETS. | ||||||||||||||||||
fieldNames | A comma-separated list of values, each representing the name of a column in the SQL query (see below). These columns represent custom fields to be associated with the newly created or updated context items. This property is optional and defaults to null. Bear in mind that the specified values are validated against the SQL query and the request will fail if the field names are not found in the SELECT clause. If the fields exist on the context type associated with the item, the values of the columns specified by this property will be imported as values of the fields with the respective technical names. If they don’t exist, then the column values will be imported as general properties of the context item. | ||||||||||||||||||
validateFieldNames | Optional. If missing or set to true, field names specified in the query will be validated. If set to false, the validation will be skipped. | ||||||||||||||||||
timeZone | Specifies the timezone of the dates in the SQL database. The default is UTC. The list of supported timezones can be found by using the following endpoints: <TM-URL>/hps/api/monitoring/options/timezone/available https://en.wikipedia.org/wiki/List_of_tz_database_time_zones | ||||||||||||||||||
sqlString | The string of the SQL query that will be executed against the datasource to fetch the items. The query is required to return (at least) the following columns (in order): id, componentId, type, description, startEvent, startTime, endEvent, endTime. The query can contain additional columns, but they should come in after these first eight columns. The extra columns are often necessary when using custom fields. Additional information about the individual columns can be found below:
An example SQL query: SELECT id, componentId, type, description, start_event, start_time, stop_event, stop_time FROM some_table WHERE :startDate <= start_time and start_time < :endDate; In addition to the required columns, the SQL query could also select:
| ||||||||||||||||||
typeMapping | A table used to map the values in the type column (see sqlString above) to actual context types in TrendMiner. Even if the type column contains a type that exists, there should be an entry in the typeMapping table that maps the type to itself, e.g.: "typeMapping": [
{ "PRODUCTION": "PRODUCTION" }
] |
Example: If the datasource contains a lastModifiedDate column, the query can be modified to select records based on their lastModifiedDate. For example:
{
...
"sqlString": "Select id, componentId, type, description, start_event, start_time, stop_event, stop_time, last_modified_date from LOGBOOK where :startDate <= last_modified_date and last_modified_date < :endDate;"...}
...
}This way, if an item is modified, it will be selected for sync, even if its start time is untouched.
The result will contain the id of the newly created query. This id will be used later.
Define a Historical Sync
This endpoint can be used to run one-time synchronization of context items at a specified time interval.
Method: POST Path: /context-sql-sync/sync Authorization header: Bearer [access_token] Body { "datasourceId": "1", "queryId": "2", "externalIdPrefix": "prefix", "startDate": "2018-10-16 12:29:01", "endDate": "2018-10-18 20:29:01", "chunkSize":1440 }
Parameter | Description |
|---|---|
datasourceId | The id of the datasource against which to run the sync. |
queryId | The id of the query to be used for the sync. |
externalIdPrefix | The prefix that will be prepended to the id obtained from the database in order to produce the external id of the context item. This prefix allows supporting the same external IDs for different data sources. |
startDate | The start of the sync interval. This is optional and can be omitted if the respective SQL query does not have parameters. |
endDate | The end of the sync interval. This is optional and can be omitted if the respective SQL query does not have parameters. |
chunkSize | The sync interval (endDate - startDate) will be split to subintervals with length specified by this value (expressed in minutes). This value is optional and defaults to null to indicate that the entire interval will be synced at one go. The value is also ignored if startDate and endDate are not specified. |
The startDate and endDate can be omitted. In this case the associated query will be run only once without parameters.
If the startDate and endDate are specified, the resulting interval is split into small subintervals based on chunkSize. Then the SQL query is executed continuously for each of the subintervals and the start and end of the subintervals are passed to the query as parameters.
The historical sync provides means to perform a “dry” run, where the data is fetched from the database and returned to the customer, but no actual context items are created. To use the dry run:
Path: /context-sql-sync/sync/test
Define a Live Sync
To use live sync, a sync job must be defined first:
Method: POST Path: /context-sql-sync/syncjob Authorization header: Bearer [access_token] Body { "datasourceId": "1", "queryId": "2", "externalIdPrefix": "prefix", "syncJobInterval": "10", "chunkSize":1440 }
Parameter | Description |
|---|---|
datasourceId | The id of the datasource against which to run the sync. |
queryId | The id of the query to be used for the sync. |
externalIdPrefix | The prefix that will be prepended to the id obtained from the database in order to produce the external id of the context item. This prefix allows supporting same external IDs for different data sources. |
syncJobInterval | The interval (expressed in minutes) between subsequent job executions. |
chunkSize | The sync interval will be split into subintervals with length specified by this value (expressed in minutes). |
The result will contain the id of the newly created sync job. This id can be used to start and stop the job. Sync job will run for the entire interval from last_sync_date till the current time. The sync jobs should be used only with queries which support parameters – positional or named.
Note
Currently last_sync_date can be determined only by checking the job’s settings in Postgres database.
To start the job:
Method: POST Path: /context-sql-sync/syncjob/{id}/start Authorization header: Bearer [access_token]
To stop a job:
Method: POST Path: /context-sql-sync/syncjob/{id}/stop Authorization header: Bearer [access_token]
After the job is started, the first time it is executed is calculated based on the syncJobInterval value. For example, if the job has syncJobInterval=10 and the job is started at 15:12, the initial job execution will happen at 15:20.
To get a list of all currently defined sync jobs:
Method: GET Path: /context-sql-sync/syncjob Authorization header: Bearer [access_token]
A sync job is started if its “scheduled” field is true.
Kerberos and Integrated Authentication
When integrated security should be used to connect to context items datasource, Kerberos must be configured and used by tm-context-sql-sync.
Create Kerberos configuration file named krb5.conf
Example:
[libdefaults]
default_realm = YYYY.CORP.CONTOSO.COM
dns_lookup_realm = false
dns_lookup_kdc = true
ticket_lifetime = 24h
forwardable = yes
[domain_realm]
.yyyy.corp.contoso.com = YYYY.CORP.CONTOSO.COM
.zzzz.corp.contoso.com = ZZZZ.CORP.CONTOSO.COM
[realms]
YYYY.CORP.CONTOSO.COM = {
kdc = krbtgt/YYYY.CORP. CONTOSO.COM @ YYYY.CORP. CONTOSO.COM
default_domain = YYYY.CORP. CONTOSO.COM
}
ZZZZ.CORP. CONTOSO.COM = {
kdc = krbtgt/ZZZZ.CORP. CONTOSO.COM @ ZZZZ.CORP. CONTOSO.COM
default_domain = ZZZZ.CORP. CONTOSO.COM
}
Copy krb5.conf to Trendminer appliance folder, i.e. /mnt/data/fileserve
In Consul’s key/value store define property “java.security.krb5.conf” for tm-context-sql-sync service. Set it’s value to “./krb5.conf”
Configure datasource as follow:
{
"name": "MSSQL_IntegratedSecurity",
"jdbcUrl": "jdbc:sqlserver://tm-
mssql21.yyyy.corp.contoso.com:1433;Integratedsecurity=true;authenticationScheme=JavaKerberos;databaseName=tm_context",
"dbType": "MSSQL",
"username": "user_name@YYYY.CORP.CONTOSO.COM",
"password": "******"
}Important Notes
Important
The access token will expire after 12 hours. Best practice is to request an access token before every API call.
Only SQL Server 2008 and later are supported. Earlier versions of MS SQL may give the following error when executing the SQL query: “Cannot find data type datetimeoffset.”
If a query is used by an active sync job, the query can not be updated.
Examples
In the examples bellow, we will use the following tm_contextitems table as context items data source:

Setup historical sync with positional parameters:
Query definition - here a positional parameter criteria is applied on a datetime field:
{ "name": "histSyncQuery1", "supportsParameters": true, "supportsNamedParameters": false, "componentLookupStrategy": "TAGS", "timeZone": "UTC", "fieldNames": " V_DLM_AVG, V_OPA_AVG", "sqlString": "SELECT id, componentId, product_code as type, 'Context item description' as description, 'START' as start_event, startDateTime, 'END' as stop_event, endDatetime, V_DLM_AVG, V_OPA_AVG FROM tm_contextitems where ? > last_modified_date and last_modified_date <= ?;", "typeMapping": [ { "B100610": "PRODUCTION" } ] }The historical sync job can be defined as follow:
{ "datasourceId": "1", "queryId": "1", "externalIdPrefix": "sync1", "chunkSize": 10, "startDate": "2020-06-24 00:00:00", "endDate": "2020-06-25 00:00:00" }Setup historical sync with named parameters:
Query definition - here a named parameter criteria is applied on a datetime field:
{ "name": "histSyncQuery2", "supportsParameters": false, "supportsNamedParameters": true, "componentLookupStrategy": "TAGS", "timeZone": "UTC", "fieldNames": " V_DLM_AVG, V_OPA_AVG", "sqlString": "SELECT id, componentId, product_code as type, 'Context item description' as description, 'START' as start_event, startDateTime, 'END' as stop_event, endDatetime, V_DLM_AVG, V_OPA_AVG FROM tm_contextitems where :startDate > last_modified_date and last_modified_date <= :endDate;", "typeMapping": [ { "B100610": "PRODUCTION" } ] }The historical sync job can be defined as follow:
{ "datasourceId": "1", "queryId": "1", "externalIdPrefix": "sync2", "chunkSize": 10, "startDate": "2020-06-24 00:00:00", "endDate": "2020-06-25 00:00:00" }Setup historical sync without parameters:
Query definition - in this case no parameters are used as query criteria:
{ "name": "histSyncQuery3", "componentLookupStrategy": "TAGS", "timeZone": "UTC", "fieldNames": " V_DLM_AVG, V_OPA_AVG", "sqlString": "SELECT id, componentId, product_code as type, 'Context item description' as description, 'START' as start_event, startDateTime, 'END' as stop_event, endDatetime, V_DLM_AVG, V_OPA_AVG FROM tm_contextitems where last_modified_date > '2020-06-24 00:00:00'", "typeMapping": [ { "B100610": "PRODUCTION" } ] }In such case no parameters are needed for historical sync job definition:
{ "datasourceId": "1", "queryId": "1", "externalIdPrefix": "sync3", "chunkSize": 10 }Setup sync job
Query definition - sync job always provides time interval, so in the query either positional or named parameters can be provided.
{ "name": "syncJobQuery1", "supportsParameters": false, "supportsNamedParameters": true, "componentLookupStrategy": "TAGS", "timeZone": "UTC", "fieldNames": " V_DLM_AVG, V_OPA_AVG", "sqlString": "SELECT id, componentId, product_code as type, 'Context item desrtiption' as description, 'START' as start_event, startDateTime, 'END' as stop_event, endDatetime, V_DLM_AVG, V_OPA_AVG FROM tm_contextitems where :startDate > last_modified_date and last_modified_date <= :endDate;", "typeMapping": [ { "B100610": "PRODUCTION" } ] }But in some cases, the query used by the sync job may not require parameters, even though an interval is provided by sync job. In such case query can be defined without parameters and different criteria can be used in the sql:
{ "name": "syncJobQuery2", "componentLookupStrategy": "TAGS", "timeZone": "UTC", "fieldNames": " V_DLM_AVG, V_OPA_AVG", "sqlString": "SELECT id, componentId, product_code as type, 'Context item description' as description, 'START' as start_event, startDateTime, 'END' as stop_event, endDatetime, V_DLM_AVG, V_OPA_AVG FROM tm_contextitems where last_modified_date < GETDATE();", "typeMapping": [ { "B100610": "PRODUCTION" } ] }In both cases, sync job definition is similar:
{ "datasourceId": "1", "queryId": "1", "externalIdPrefix": "prefix", "syncJobInterval": "10", "chunkSize": 10 }
Example
Step | Visual | Detail |
|---|---|---|
Configure Custom Fields for Context Item Types | 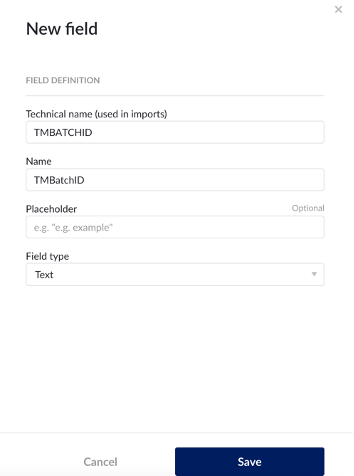 | Configure in ConfigHub on an admin account |
Create and Context Item Types (include custom fields) | 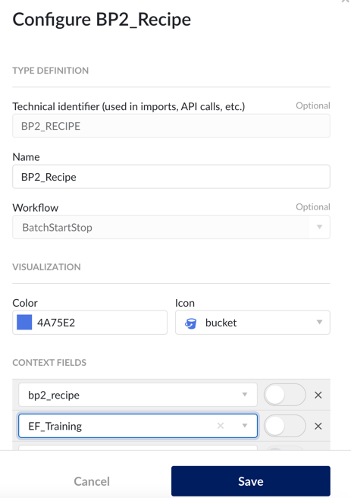 | Configure in ConfigHub on an admin account |
Create SQL Table | 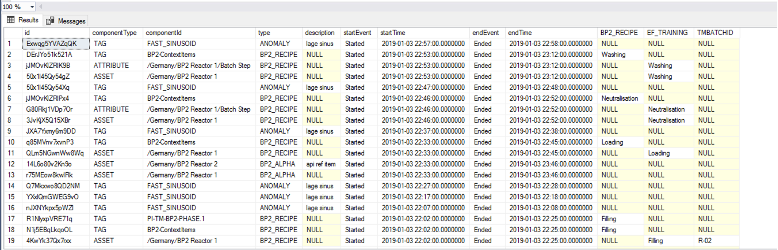 | Configure in ConfigHub on an admin account Create SQL Table Tables must include id, componentType, type, description, startEvent, startTime, endEvent, and endTime. After that, custom fields can be added as additional columns. Note that in your case, “componentid”, “componenttype”, and “type” column will all likely be the same values for batch sheets. Componentid is the tag the context item will be associated with, componenttype will likely be TAG, and the type will be the name of the Context Item type you created (ex. Batch Sheet) |
Define the data source | 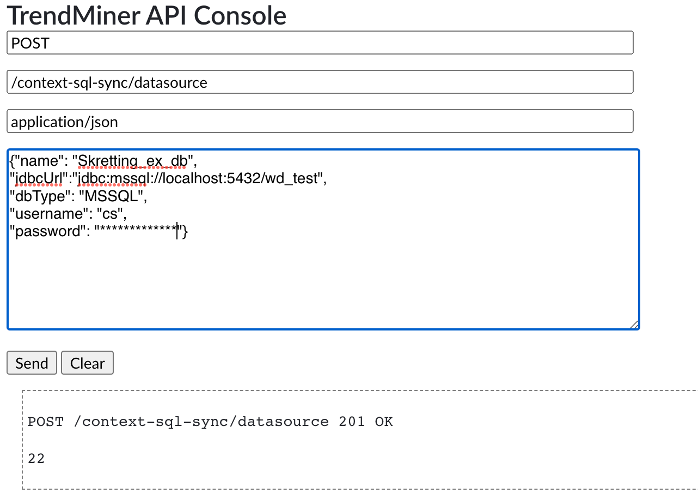 Use the TrendMiner API console to obtain data-sourced for sync in later steps: 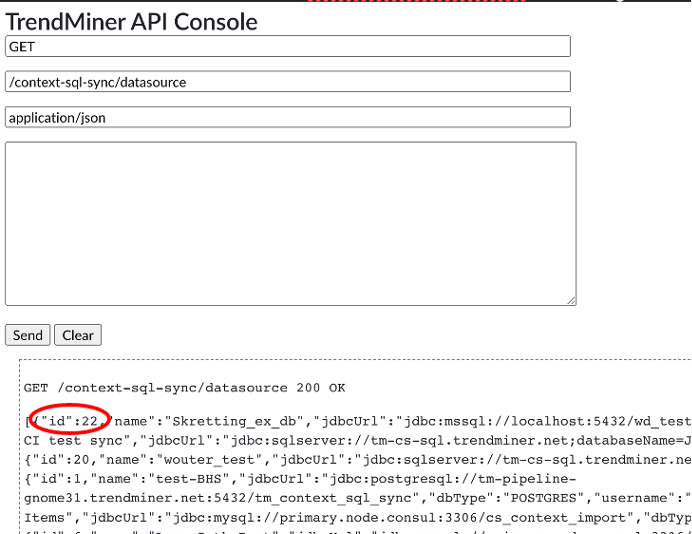 | |
Define the Query | 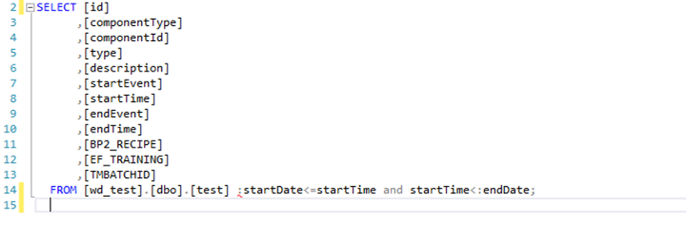 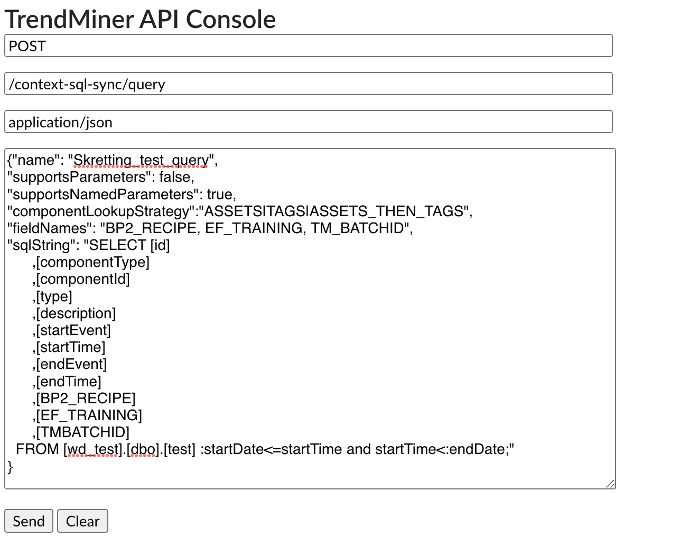  | The rows from id to endTime are required, and additional custom fields can be added after. startDate and endDate will be defined in the syncs. Test the query within your environment to verify functionality prior to posting via API. |
Historical Sync |  | datasourceId and queryId are found using the GET method strings shown in previous steps. Locate the number of the desired database and query. Prefix is not required, but can be used to collect context items with the same name from different data sources (ex. using batch id to label different context item types). NoteWe recommend inputting a chunksize of 1440 |
Define Sync Job |   | This sync job will sync with the SQL database every 10 minutes. |
Live Sync Job |  | This will schedule ongoing syncs of the defined database at the defined syncJobInterval. This example assumes that sync job id is 14. |