How to set up an AWS IoT SiteWise data source?
The following sections will detail all the information needed for setting up an AWS IoT SiteWise data source in TrendMiner.
Communication flows
One can configure AWS IoT SiteWise to store data in following storage tiers: a hot tier optimized for real-time applications, and a cold tier optimized for analytical applications.
hot tier - a service-managed database. By default, your data is stored only in the hot tier of AWS IoT SiteWise. You can set a retention period for how long your data is stored in the hot tier before it's deleted. The hot tier can be queried through the AWS REST API.
cold tier – a customer-managed Amazon S3 bucket. AWS IoT SiteWise stores your data in an Amazon S3 bucket. You can use the cold tier to store historical data that requires infrequent access. Latency might be higher when you retrieve cold tier data. After your data is sent to the cold tier, you can use the Amazon Athena AWS service to run SQL queries on your data.
The cold tier requires additional configuration in AWS with regards to S3 and a Glue crawler. For more information about this, please consult the AWS documentation.
Setup an AWS IoT SiteWise data source
To add an AWS IoT SiteWise data source, in ConfigHub go to Data in the left side menu, then Data sources, choose + Add data source.
Type name of data source, select “AWS IoT SiteWise” from the Provider dropdown. Selecting the capabilities for the data source with the given checkboxes will open additional properties to enter, grouped in following sections:
Connection details – lists properties related to the configuration of the connection that will be established with AWS IoT SiteWise
Time series configuration – lists properties relevant for the time series data
Asset configuration – lists properties relevant for the asset data
Context configuration – lists properties relevant for the AWS IoT SiteWise alarms
Important
The time series storage in AWS IoT SiteWise is structured according to the asset hierarchy. No time series data can be obtained without first pulling the asset tree, and then based on it the time series data can be obtained.
As the time series and asset capabilities go hand in hand in AWS IoT SiteWise, the checkboxes for Asset and Time series capabilities must be selected together.
To pull AWS IoT SiteWise alarm data select the Context capability checkbox.
Asset capability
With this capability enabled the datasource can pull assets from AWS IoT SiteWise to be synced into a TrendMiner asset structure.
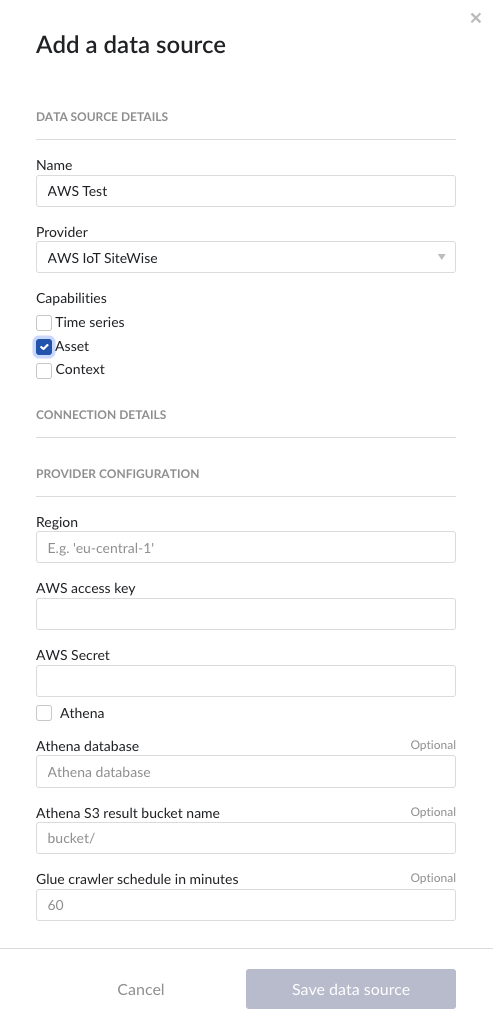
Following properties need to be populated:
“Name“ - а mandatory name needs to be specified.
“Provider” - select the option AWS IoT SiteWise from the dropdown.
“Capabilities” - the AWS IoT SiteWise provider supports the Asset, Time series and Context capabilities.
"Region" – enter the availability zone region within AWS cloud in which the AWS IoT SiteWise instance is configured. For more information, please consult the AWS documentation.
"AWS access key" – enter the access key to authenticate. The AWS access key as generated in AWS IAM. For more information, please consult the AWS documentation.
"AWS Secret" – enter the secret to authenticate. The AWS secret as generated in AWS IAM. For more information, please consult the AWS documentation.
“Athena”
if the Athena option is not enabled, the provider will ingest hot tier data only, using the AWS IoT SiteWise REST API.
if the Athena option is enabled the provider will ingest also cold tier data using Athena queries.
“Athena database” - the name of the Athena database. For more information, please consult the AWS documentation.
“Athena S3 result bucket name” - Athena query results are stored after execution in a S3 result bucket. Specify here the name of the bucket. For more information, please consult the AWS documentation.
“Glue crawler schedule in minutes” - value of Glue crawler interval in minutes. For more information, please consult AWS documentation.
Time series capability
With this capability enabled the datasource can sync Metrics, Transforms and Measurements from AWS IoT SiteWise into TrendMiner tags.
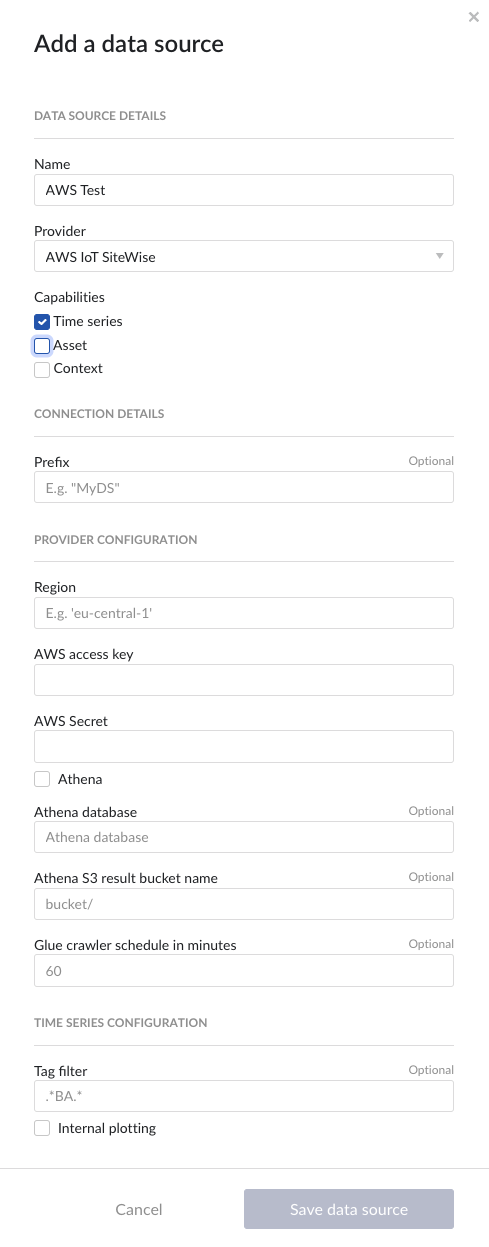
Following properties need to be populated:
“Name“ - а mandatory name needs to be specified.
“Provider” - select the option AWS IoT SiteWise from the dropdown.
“Capabilities” - the AWS IoT SiteWise provider supports the Asset, Time series and Context capabilities.
“Prefix” - optional text can be entered here that will be used to prefix the tag names in TrendMiner, if a value is entered. Warning: this cannot be changed. The datasource can however be deleted and you can start the configuration over again.
“Tag filter” - an optional regular expression to be entered. Only tags with names that match this regex will be retained when creating tags (using the tag list query).
"Region" – enter the availability zone region within AWS cloud in which the AWS IoT SiteWise instance is configured. For more information, please consult the AWS documentation.
"AWS access key" – enter the access key to authenticate. The AWS access key as generated in AWS IAM. For more information, please consult the AWS documentation.
"AWS Secret" – enter the secret to authenticate. The AWS secret as generated in AWS IAM. For more information, please consult the AWS documentation.
“Athena”
if the Athena option is not enabled, the provider will ingest hot tier data only, using the AWS IoT SiteWise REST API.
if the Athena option is enabled the provider will ingest also cold tier data using Athena queries.
“Athena database” - the name of the Athena database. For more information, please consult the AWS documentation.
“Athena S3 result bucket name” - Athena query results are stored after execution in a S3 result bucket. Specify here the name of the bucket. For more information, please consult the AWS documentation.
“Glue crawler schedule in minutes” - value of Glue crawler interval in minutes. For more information, please consult AWS documentation.
Context capability
With this capability enabled the datasource can sync Alarms from IoT SiteWise into TrendMiner context items.
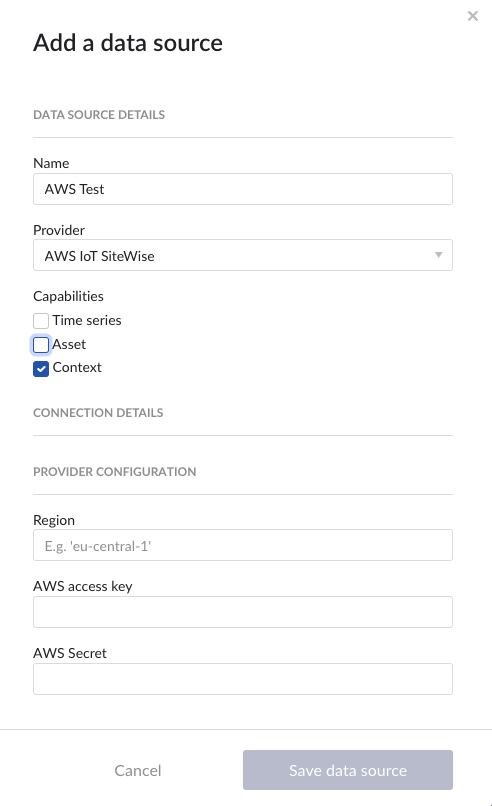
Following properties need to be populated:
“Name“ - а mandatory name needs to be specified.
“Provider” - select the option AWS IoT SiteWise from the dropdown.
“Capabilities” - the AWS IoT SiteWise provider supports the Asset, Time series and Context capabilities.
"Region" – enter the availability zone region within AWS cloud in which the AWS IoT SiteWise instance is configured. For more information, please consult the AWS documentation.
"AWS access key" – enter the access key to authenticate. The AWS access key as generated in AWS IAM. For more information, please consult the AWS documentation.
"AWS Secret" – enter the secret to authenticate. The AWS secret as generated in AWS IAM. For more information, please consult the AWS documentation.
Setting up S3, Glue, Athena
The very first thing that needs to be done is the creation of the S3 bucket. To do that, we need to provide the bucket name and the region. There are specific rules about the bucket name which could be found here. You can also refer to the step by step guide to create an S3 bucket.
To be able to read data from S3, the AWS IoT SiteWise storage needs to be enabled with the following configuration:
Left menu → Settings → Storage → Edit storage.
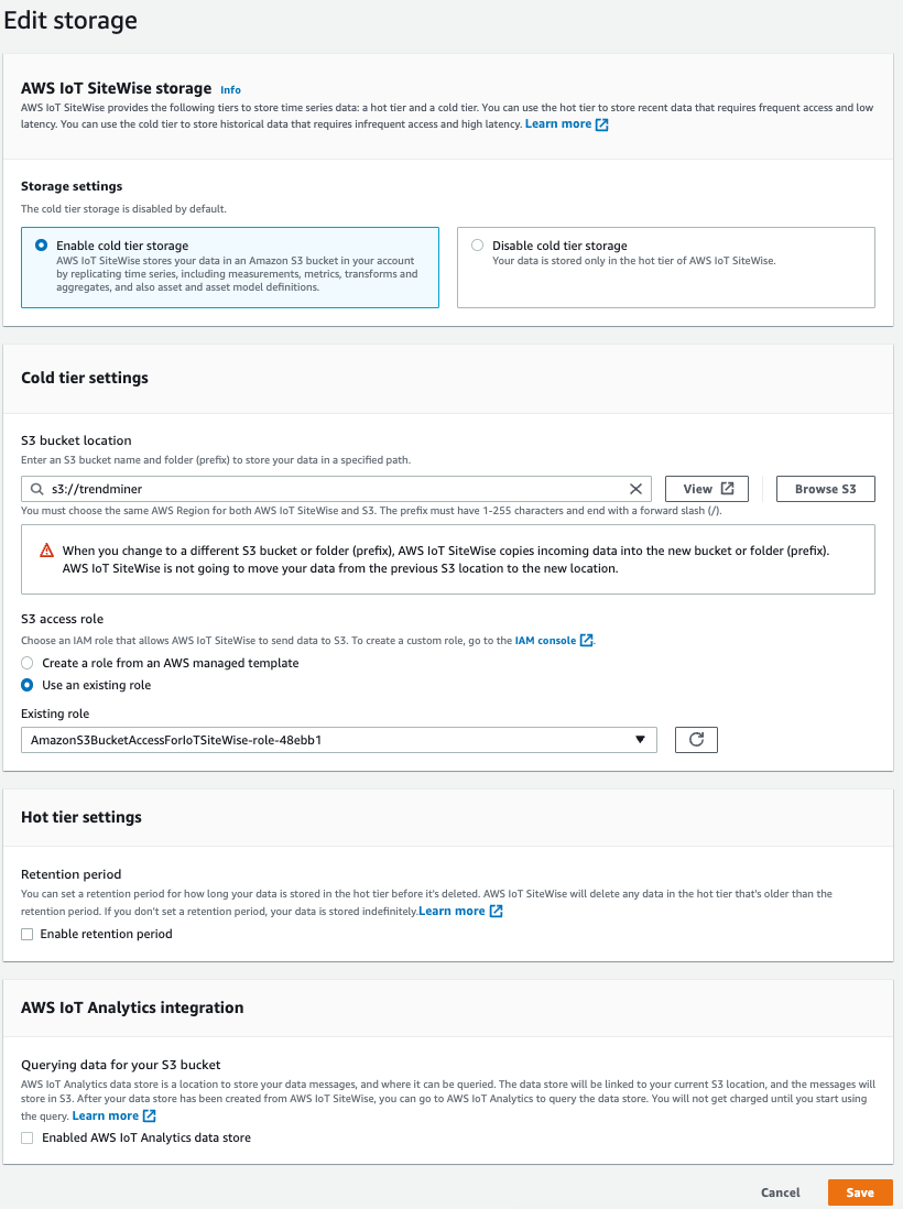
The creation of the role needs the following policies. Pay attention at the bucket name: "arn:aws:s3:::trendminer"

Refer to the AWS documentation on configuring storage settings.
Database creation - not mandatory as a separate step. The name must be unique.
Configuring a crawler:
Example configuration.
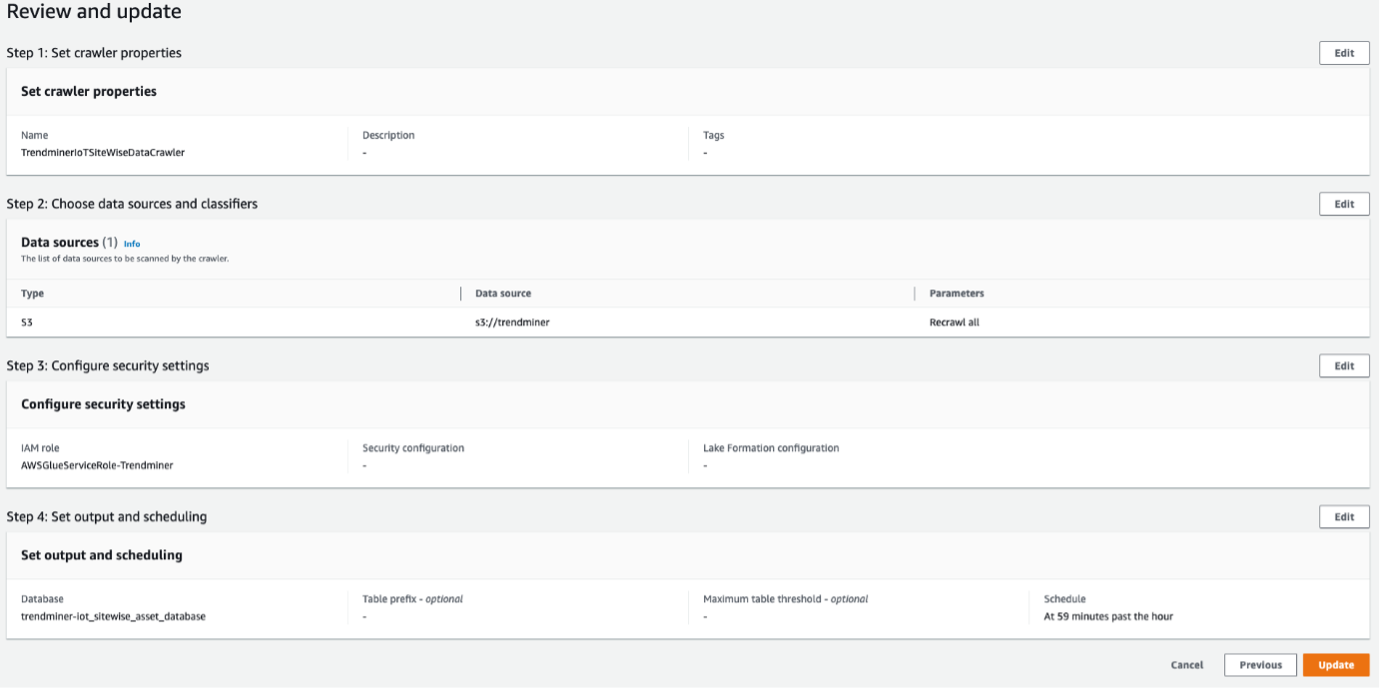
Once the configuration is done, you need to manually Run the crawler. This process might take several minutes, so you should wait until the state becomes Ready.
You can refer to the AWS Documentation on creating a Glue crawler.
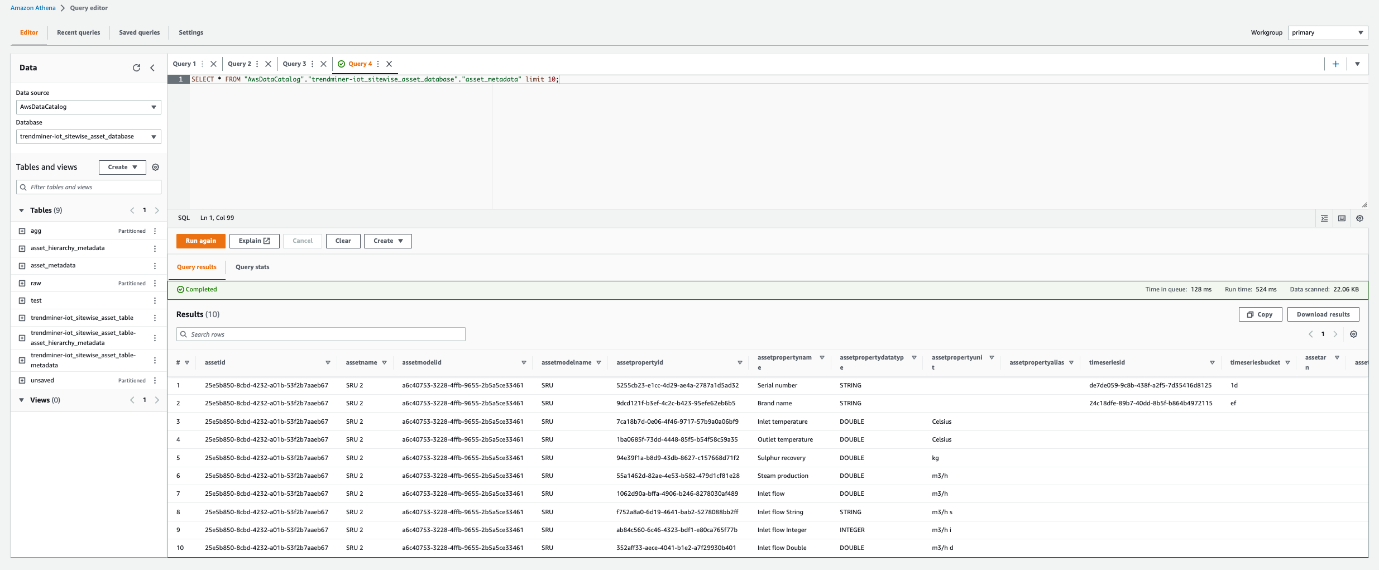
Once your crawler status is Ready, you can query your data:
In the navigation pane Data Catalog → Databases → Tables → asset_metadata table of your database and click on the Table data link (more information on how crawlers work - here).
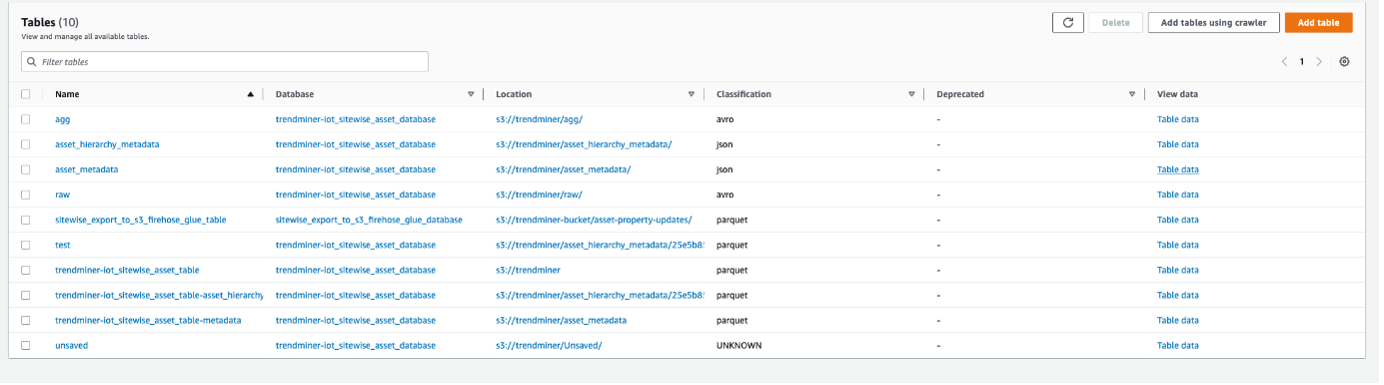
Select the table and continue.

A confirmation pop-up appears. By clicking Proceed you will be automatically redirected to AWS Athena.
Once your crawler runs successfully, you are redirected to AWS Athena:
Provide a configuration about the Query result location.
Provide your S3 bucket location.

A query can be executed now.
Refer to the AWS Documentation on how to query data with Athena.