How to set up a Generic JDBC data source?
Notice
The documentation to set up these connectivity options is provided as a reference. However, expert knowledge is required to configure and set these up successfully. Therefore, TrendMiner and TrendMiner's implementation partners offer these as a service. Support to troubleshoot and/or optimize connections will not be provided without a service agreement. Contact TrendMiner support to receive a quote or get in touch with implementation partners.
Creating Generic JDBC provider
To integrate with and ingest data from a database that supports JDBC, a datasource of provider type Generic JDBC can be added and configured in ConfigHub.
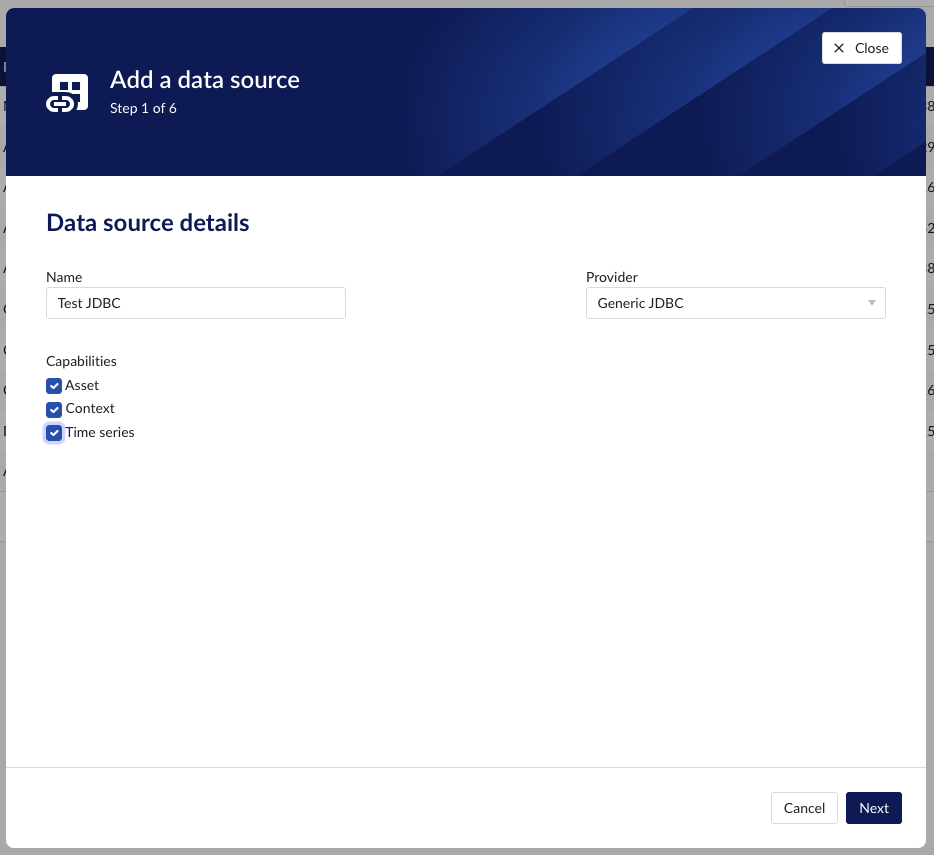
To add a Generic JDBC data source, in ConfigHub go to Data in the left side menu, then Data sources, choose + Add data source. Fill out 'Data source details' on the first step of the datasource creation wizard: type the name of the data source, select “Generic JDBC” from the Provider dropdown. Selecting the capabilities for the data source with the given checkboxes will open additional properties to enter, grouped in following sections:
Connection details - lists properties related to the configuration of the connection that will be established with datasource
Provider details - lists properties shared by multiple capabilities
Time series details – lists properties relevant for the time series data
Asset details - lists properties relevant for asset data
Context details - lists properties relevant for context data
Connection properties
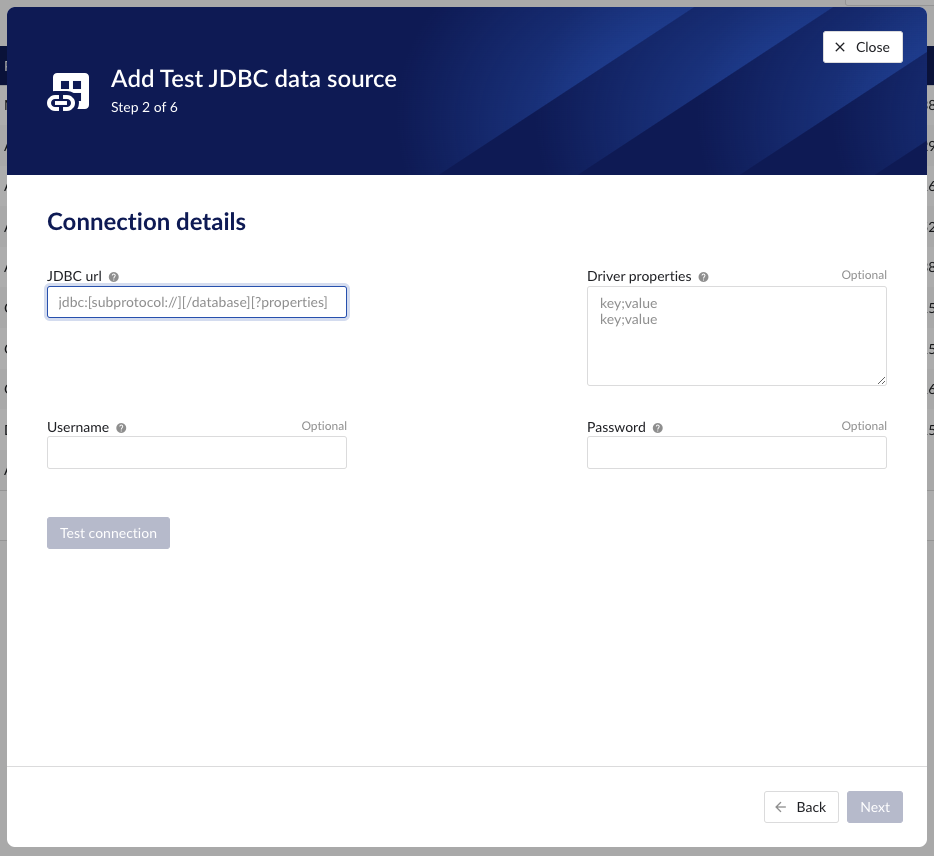
Following properties need to be populated to establish the connection to the JDBC provider:
“Name“ - а mandatory name needs to be specified.
"Provider" - select the option "Generic JDBC" from the dropdown.
"Capabilities" - the Generic JDBC provider supports the Time series, Asset and Context capabilities.
“Prefix” - optional text can be entered here that will be used to prefix the tag names in TrendMiner, if a value is entered. Warning: this cannot be changed. The datasource can however be deleted and you can start the configuration over again.
"JDBC url" - a mandatory JDBC url to establish a connection to.
"Driver properties" - additional optional driver specific properties can be configured here as key;value, where key is the name of driver specific property and value the desired value for this property. Please consult the documentation of the specific JDBC driver for more information.
"Username" - optional convenience field to enter the username used to establish a database connection. As an alternative this information can be entered through the driver properties.
"Password" - optional convenience field to enter the password used to establish a database connection. As an alternative this information can be entered through the driver properties.
Following properties are shared by multiple capabilities:
"Delimiter" - optional delimiter override, used to parse data values of type STRING_ARRAY. The default is a comma (,)."Delimiter" - optional delimiter override, used to parse data values of type STRING_ARRAY. The default is a comma (,)
Time series properties
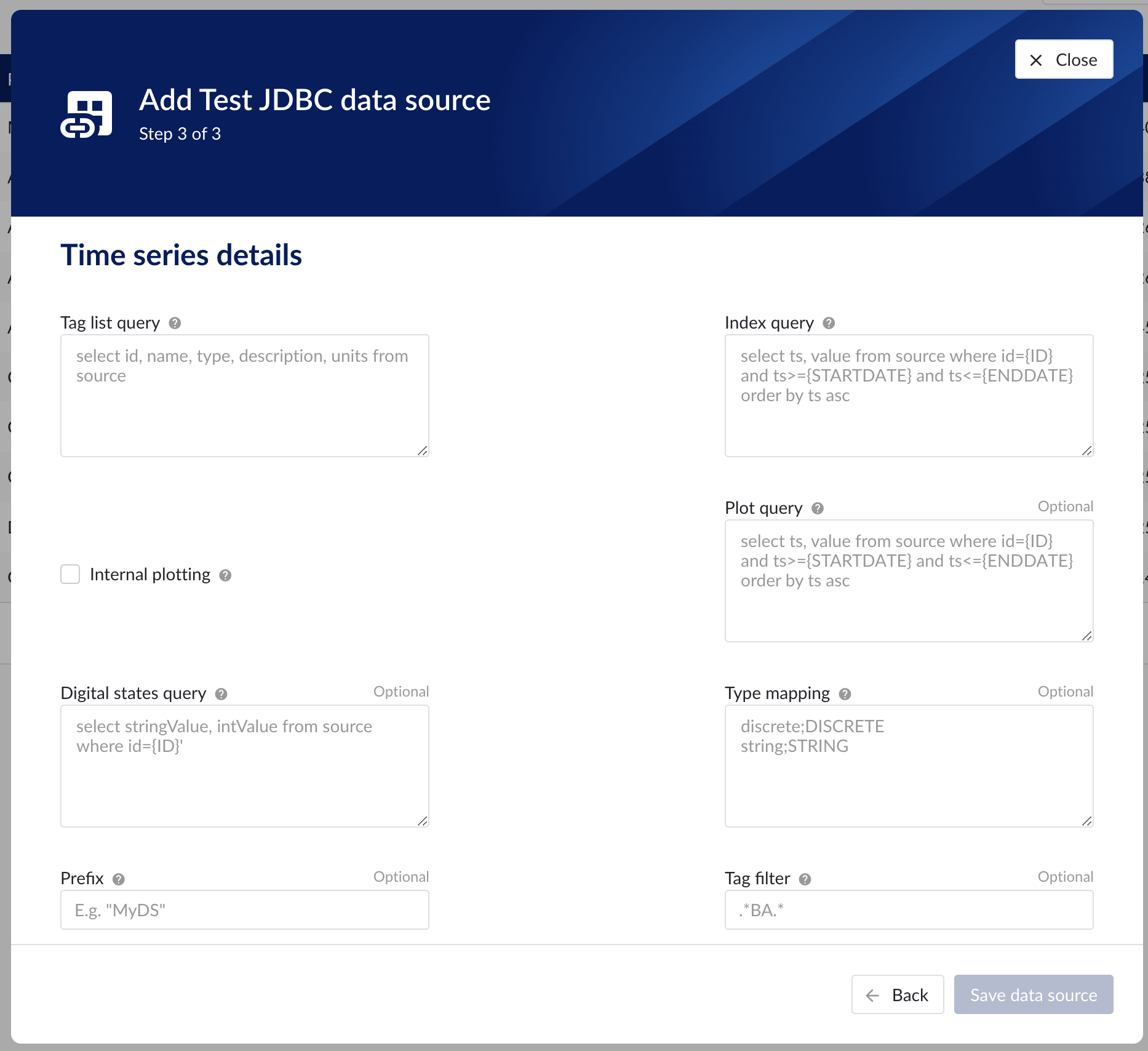
Following properties need to be entered to enable time series capability:
“Tag list query” - a query used by TrendMiner to create tags. A query needs to be provided that given the database schema and tables used will return the following columns:
id - this is mandatory and must have a unique value for each row returned by the query.
name - this is mandatory and must have a value.
type - an optional type indication. If the type column is not in the query, TrendMiner will use the default type which is ANALOG. Custom types can be returned here not known to TrendMiner but then a type mapping must be added as well. See also type mapping below. Without additional type mapping it must be one of the following TrendMiner tag types: ANALOG, DIGITAL, DISCRETE, STRING
description - an optional description to describe the tag. Can return an empty value or null.
units - an optional indication of the units of measurement for this tag. Can return an empty value or null.
“Index query” - a query used by TrendMiner to ingest timeseries data for a specific tag. The query is expected to return a ts (timestamp) and a value. The following variables are available to be used in the WHERE clause of this query. The variables will be substituted at query execution with values. There should not be any NULL values returned by the SELECT statement so including "IS NOT NULL" in the WHERE clause is strongly recommended.
{ID}. The id as returned by the tag list query.
{STARTDATE} TrendMiner will ingest data per intervals of time. This denotes the start of such an interval.
{ENDDATE} TrendMiner will ingest data per intervals of time. This denotes the end of such an interval.
{INTERPOLATION}: Interpolation type of a tag, which can be one of two values: LINEAR or STEPPED.
{INDEXRESOLUTION}: Index resolution in seconds. It can be used to optimise a query to return the expected number of points.
“Internal plotting” - When internal plotting is disabled, TrendMiner uses the configured plot query (if provided) to fetch aggregated/interpolated data directly from the data source when zooming in or when index data is unavailable, minimizing server load and network traffic; if no plot query is configured, it falls back to the tag's index data, which implies no tag data can be displayed until the tag is indexed. When internal plotting is enabled, any configured plot query is ignored entirely, and TrendMiner instead uses the index query to aggregate data internally, consuming more server resources and network bandwidth. Internal plotting should only be used when no performant plot query can be provided.
“Plot query” – a query used by TrendMiner to plot timeseries data for a specific tag. The query is expected to return a ts (timestamp) and a value. The following variables are available to be used in the WHERE clause of this query. The variables will be substituted at query execution with values. There should not be any NULL values returned by the SELECT statement so including "IS NOT NULL" in the WHERE clause is strongly recommended.
{ID}. The id as returned by the tag list query.
{STARTDATE}. TrendMiner will plot data per intervals of time. This denotes the start of such an interval.
{ENDDATE}. TrendMiner will plot data per intervals of time. This denotes the end of such an interval.
{INTERPOLATION}: Interpolation type of a tag, which can be one of two values: LINEAR or STEPPED.
{INDEXRESOLUTION}: Index resolution in seconds. It can be used to optimise a query to return the expected number of points.
“Digital states query” - if tags of type DIGITAL are returned by the tag list query, TrendMiner will use this query to ask for the {stringValue, intValue} pairs for a specific tag to match a label with a number. The query expects to return a stringValue and an intValue and can make use of the {ID} variable in the where clause. The variable will be substituted at query execution with a value.
“Tag filter” - an optional regular expression to be entered. Only tags with names that match this regex will be retained when creating tags (using the tag list query).
“Type mapping” - if types differ from what TrendMiner uses and one wants to avoid overcomplicating the query, a type mapping can be entered here. It can contain multiple lines and expect per line the value to be representing a custom type followed by a ; and a TrendMiner type. During the execution of the tag list query TrendMiner will then use this mapping to map the custom values returned in the query to TrendMiner tag types.
customTypeA;ANALOG
customTypeB;DIGITAL
customTypeC;DISCRETE
customTypeD;STRING
"Datetime format" - optional format your time series data are stored in.
"Timezone" – optional timezone your times series data are stored in. Default is "UTC". The format of the timezone is as defined in the IANA time zone database. Valid timezone examples are:
"Europe/Brussels"
"America/Chicago"
"Asia/Kuala_Lumpur"
Asset properties
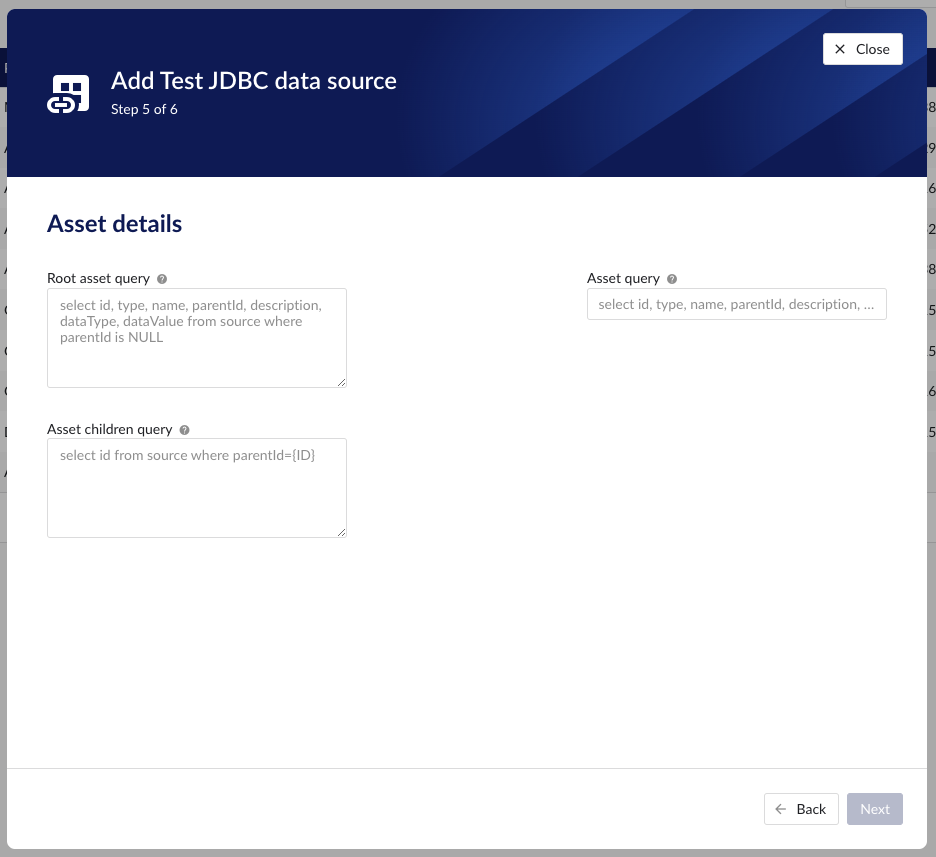
Following properties need to be entered to enable asset capability:
"Root asset query" - this query is responsible for returning all top level elements from the asset tree structure. It will be used to traverse further down the tree using to queries below. The order of the columns in the result needs to be:
id. Required, unique identifier for this asset record.
type. Required, TrendMiner can handle asset of type ASSET or ATTRIBUTE. This column must be one of these two values.
name. Required, name for this asset record.
description. Optional, description for this asset record.
data type. Optional, TrendMiner can ingest 4 different types of data in case the asset is of type ATTRIBUTE. This column will impact on how the data value column will be interpreted:
STRING data value is interpreted as text
STRING_ARRAY comma delimited string
NUMERIC
DATA_REFERENCE
data value. Optional, this column will either be interpreted as text (STRING), a collection of text (STRING_ARRAY), a number (NUMERIC), or a reference to a tag (DATA_REFERENCE).
"Asset query" - this query returns details for a specific asset record. The following variables are available to be used in the where clause of this query. The variables will be substituted at query execution with values:
{ID}. The id as the unique asset identification.
The order of the columns in the result needs to be:
id. Required, unique identifier for this asset record.
type. Required, TrendMiner can handle asset of type ASSET or ATTRIBUTE. This column must be one of these two values.
name. Required, name for this asset record.
description. Optional, description for this asset record.
data type. Optional, TrendMiner can ingest 4 different types of data in case the asset is of type ATTRIBUTE. This column will impact on how the data value column will be interpreted:
STRING data value is interpreted as text
STRING_ARRAY comma delimited string
NUMERIC
DATA_REFERENCE
data value. Optional, this column will either be interpreted as text (STRING), a collection of text (STRING_ARRAY), a number (NUMERIC), or a reference to a tag (DATA_REFERENCE).
"Asset children query" - this query returns the ids of the direct descendants of the asset. The id passed is the parent, the records returned are its child nodes. The following variables are available to be used in the where clause of this query. The variables will be substituted at query execution with values:
{ID}. The id as the unique asset identification.
The order of the columns in the result needs to be:
id. Required, unique identifier for this asset record.
Context properties
Following properties need to be entered to enable context capability:
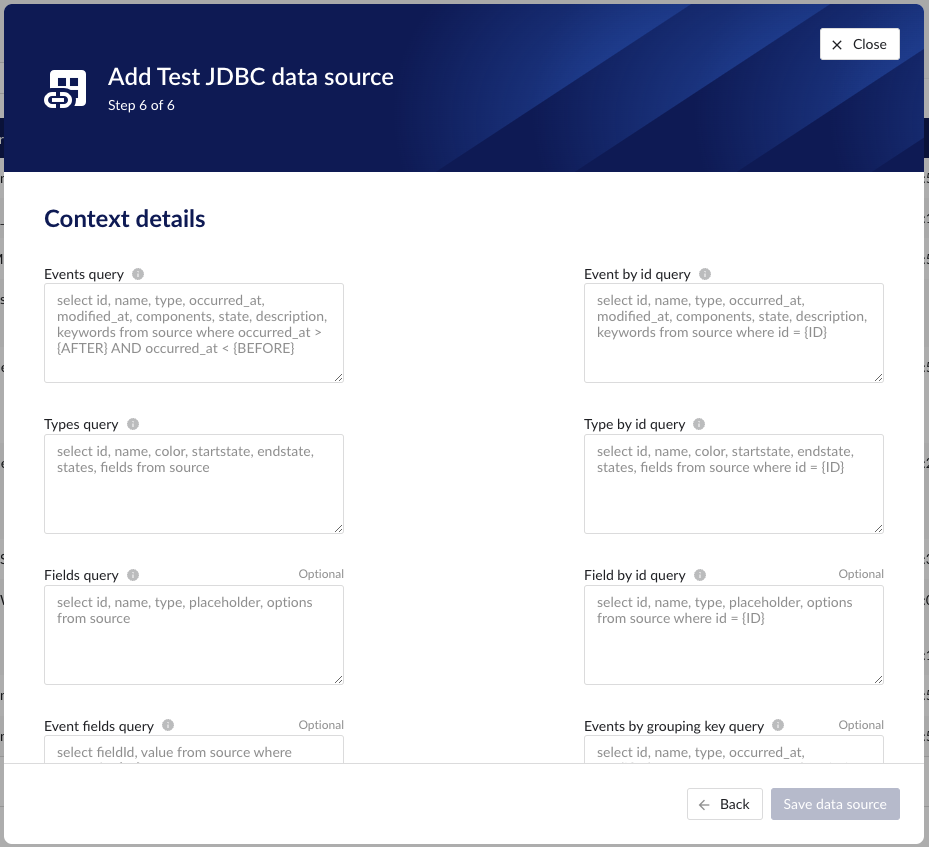
"Events query" - this query is responsible for returning events from the source database. Context items will be generated based on these events.
{AFTER}and{BEFORE}placeholders can be used in the query. They will be replaced with values received in the API call. AdditionalEvent fields querywill be executed to populate custom field values for a specific event. The order of the columns in the result needs to be:id. Required, unique identifier for this event record.
name. Required, name for this event record.
type. Required, event type id. Full information about event type will be fetched in
Type by id query.occurred_at. Required, timestamp when the event has occurred.
modified_at. Required, timestamp when the event was modified.
components. Required, list of component (asset) ids separated by the Delimiter (',' by default).
Notice
It is not possible to link events directly to tags using the generic JDBC provider. Create an asset structure before syncing events.
state. Optional, state for this event record.
description. Optional, description for this event record.
keywords. Optional, list of keywords separated by the Delimiter (',' by default).
"Event by id query" - this query is responsible for returning a specific event from the source database.
{ID}placeholder can be used in the query. It will be replaced with the value received in the API call. AdditionalEvent fields querywill be executed to populate custom field values for specific event. The order of the columns in the result needs to be:id. Required, unique identifier for this event record.
name. Required, name for this event record.
type. Required, event type id. Full information about event type will be fetched in
Type by id query.occurred_at. Required, timestamp when the event has occurred.
modified_at. Required, timestamp when the event was modified.
components. Required, list of component (asset) ids separated by the Delimiter (',' by default).
Notice
It is not possible to link events directly to tags using the generic JDBC provider. Create an asset structure before syncing events.
state. Optional, state for this event record.
description. Optional, description for this event record.
keywords. Optional, list of keywords separated by the Delimiter (',' by default).
"Types query" - this query is responsible for returning a list of possible event types from the source database. The order of the columns in the result needs to be:
id. Required, unique identifier for this event record.
name. Required, name for this event record.
color. Optional, color for this event type record. It will be used in the Gantt chart view of the ContextHub.
startstate. Optional, name of the start state.
endstate. Optional, name of the end state.
states. Optional, list of possible states separated by the Delimiter (',' by default).
fields. Optional, list of custom field definition ids for this event record separated by the Delimiter (',' by default).
"Type by id query" - this query is responsible for returning an event type from the source database.
{ID}placeholder can be used in the query. It will be replaced with the value received in the API call. The order of the columns in the result needs to be:id. Required, unique identifier for this event record.
name. Required, unique identifier for this event record.
color. Optional, color for this event type record. It will be used in the Gantt chart view of the ContextHub.
startstate. Optional, name of the start state.
endstate. Optional, name of the end state.
states. Optional, list of possible states separated by the Delimiter (',' by default).
fields. Optional, list of custom field definition ids for this event record separated by the Delimiter (',' by default).
"Fields query" - this query is responsible for returning a list of possible custom fields from the source database. The order of the columns in the result needs to be:
id. Required, unique identifier for this field record.
name. Required, name for this field record.
type. Required, possible values:
STRING
NUMERIC
ENUMERATION
placeholder. Optional, placeholder will be displayed in the ContextHub event creation form.
options. Optional, if type is
ENUMERATIONthis value is required. A list of possible values separated by the Delimiter (',' by default).
"Field by id query" - this query is responsible for returning a custom field from the source database.
{ID}placeholder can be used in the query. It will be replaced with the value received in the API call. The order of the columns in the result needs to be:id. Required, unique identifier for this field record.
name. Required, name for this field record.
type. Required, possible values:
STRING
NUMERIC
ENUMERATION
placeholder. Optional, placeholder will be displayed in the ContextHub event creation form.
options. Optional, if type is
ENUMERATIONthis value is required. A list of possible values separated by the Delimiter (',' by default).
"Event fields query" - this query is responsible for returning custom field values for specific event.
{ID}placeholder can be used in the query. It represents an event id and will be replaced with the value received in the API call. The order of the columns in the result needs to be:fieldId. Required, unique identifier of custom field definition (provided in the Fields query).
value. Required, field value.
"Events by grouping key query" - this query is responsible for returning event(s) with the same grouping key from the source database .
{GROUPINGKEY}placeholder can be used in the query. It will be replaced with values received in the API call. The order of the columns in the result needs to be:id. Required, unique identifier for this event record.
name. Required, name for this event record.
type. Required, event type id. Full information about event type will be fetched in
Type by id query.occurred_at. Required, timestamp when the event has occurred.
modified_at. Required, timestamp when the event was modified.
components. Required, list of component (asset) ids separated by the Delimiter (',' by default).
Notice
It is not possible to link events directly to tags using the generic JDBC provider. Create an asset structure before syncing events.
state. Optional, state for this event record.
description. Optional, description for this event record.
keywords. Optional, list of keywords separated by the Delimiter (',' by default).
"Events Sort column" - column name that will be used for sorting and paging of the events. If value is not set, "id” column will be used by default.
"Events sort column DataType" - the data type of Events sort column. Possible values are: Text, Numeric, DateTime. If value is not set, 'Text' value will be used by default.
"Events id column DataType" - the data type of Events id column (used in Event by id query). Possible values are: Text, Numeric, DateTime. If value is not set, 'Text' value will be used by default.
Example queries - Postgres
Time series capability
Tag list query
select id, name, type, description, units from source
Index query
select ts, value from source where id={ID} and ts between TO_TIMESTAMP({STARTDATE}, 'YYYY/MM/DD HH24:MI:SS') and TO_TIMESTAMP({ENDDATE}, 'YYYY/MM/DD HH24:MI:SS') and value IS NOT NULL order by ts ascPlot query
select ts, value from source where id={ID} and ts between TO_TIMESTAMP({STARTDATE}, 'YYYY/MM/DD HH24:MI:SS') and TO_TIMESTAMP({ENDDATE}, 'YYYY/MM/DD HH24:MI:SS') and value IS NOT NULL o rder by ts ascDigital states query
This query is applicable when there are tags of type STRING returned through the tag list query.
select stringValue, intValue from source where id={ID}Asset capability
Root asset query
select id, type, name, parentId, description, dataType, dataValue from source where parentId is NULL
Asset query
select id, type, name, description, dataType, dataValue from source where id in ({IDS})Asset children query
select id from source where parentId={ID}Context capability
Events query
select id, name, type, occurred_at, modified_at, components, state, description, keywords from source where occurred_at > TO_TIMESTAMP({AFTER}, 'YYYY/MM/DD HH24:MI:SS') and occurred_at < TO_TIMESTAMP({BEFORE}, 'YYYY/MM/DD HH24:MI:SS')Event by id query
select id, name, type, occurred_at, modified_at, components, state, description, keywords from source where id = {ID}Event types query
select id, name, color, startstate, endstate, states, fields from source
Event type by id query
select id,name, color, startstate, endstate, states, fields from source where id = {ID}Fields query
select id, name, type, placeholder, options from source
Field by id query
select id, name, type, placeholder, options from source where id = {ID}Event fields linked to event query
select fieldId, value from source where eventId = {ID}Events by grouping key query
select id, name, type, occurred_at, modified_at, components, state, description, keywords, grouping_key from source where grouping_key = {GROUPINGKEY}
Example queries - MariaDB
Time series capability
Tag list query
select id, name, type, description, units from source
Index query
select ts, value from source where id={ID} and ts >= STR_TO_DATE({STARTDATE}, '%Y-%m-%d %H:%i:%S') and ts <=STR_TO_DATE({ENDDATE}, '%Y-%m-%d %H:%i:%S') order by ts ascPlot query
select ts, value from source where id={ID} and ts >= STR_TO_DATE({STARTDATE}, '%Y-%m-%d %H:%i:%S') and ts <=STR_TO_DATE({ENDDATE}, '%Y-%m-%d %H:%i:%S') order by ts ascDigital states query
This query is applicable when there are tags of type STRING returned through the tag list query.
Select stringValue, intValue from source where id={ID}Asset capability
Root asset query
select id, type, name, parentId, description, dataType, dataValue from source where parentId is NULL
Asset query
select id, type, name,description, dataType, dataValue from source where id in ({IDS})Asset children query
select id from source where parentId={ID}Context capability
Events query
select id, name, type, occurred_at, modified_at, components, state, description, keywords from source where occurred_at > STR_TO_DATE({AFTER}, '%Y-%m-%d %H:%i:%S') and occurred_at < STR_TO_DATE({BEFORE}, '%Y-%m-%d %H:%i:%S')Event by id query
select id, name, type, occurred_at, modified_at, components, state, description, keywords from source where id = {ID}Event types query
select id, name, color, startstate, endstate, states, fields from source
Event type by id query
select id,name, color, startstate, endstate, states, fields from source where id = {ID}Fields query
select id, name, type, placeholder, options from source
Field by id query
select id, name, type, placeholder, options from source where id = {ID}Event fields linked to event query
select fieldId, value from source where eventId = {ID}Events by grouping key query
select id, name, type, occurred_at, modified_at, components, state, description, keywords, grouping_key from source where grouping_key = {GROUPINGKEY}Example queries - SQLite
Time series capability
Tag list query
select id, name, type, description, units from source
Index query
select ts, value from source where id={ID} and ts>={STARTDATE} and ts<={ENDDATE} order by ts ascPlot query
select ts, value from source where id={ID} and ts>={STARTDATE} and ts<={ENDDATE} order by ts ascDigital states query
This query is applicable when there are tags of type STRING returned through the tag list query.
select stringValue, intValue from source where id={ID}Asset capability
Root asset query
select id, type, name, parentId, description, dataType, dataValue from source where parentId is NULL
Asset query
select id, type, name, description, dataType, dataValue from source where id in ({IDS})Asset children query
select id from source where parentId={ID}Context capability
Events query
select id, name, type, occurred_at, modified_at, components, state, description, keywords from source where occurred_at >{AFTER} and occurred_at <{BEFORE}Event by id query
select id, name, type, occurred_at, modified_at, components, state, description, keywords from source where id = {ID}Event types query
select id, name, color, startstate, endstate, states, fields from source
Event type by id query
select id,name, color, startstate, endstate, states, fields from source where id = {ID}Fields query
select id, name, type, placeholder, options from source
Field by id query
select id, name, type, placeholder, options from source where id = {ID}Event fields linked to event query
select fieldId, value from source where eventId = {ID} Events by grouping key query
select id, name, type, occurred_at, modified_at, components, state, description, keywords, grouping_key from source where grouping_key = {GROUPINGKEY}Example queries - MSSQL
Time series capability
Tag list query
select id, name, type, description, units from source
Index query
select ts, value from source where id={ID} and ts between convert(DATETIME, {STARTDATE}, 127) and convert(DATETIME, {ENDDATE}, 127) order by ts ascPlot query
select ts, value from source where id={ID} and ts between convert(DATETIME, {STARTDATE}, 127) and convert(DATETIME, {ENDDATE}, 127) order by ts ascDigital states query
This query is applicable when there are tags of type STRING returned through the tag list query.
select stringValue, intValue from source where id={ID}Asset capability
Root asset query
select id, type, name, parentId, description, dataType, dataValue from source where parentId is NULL
Asset query
select id, type, name, description, dataType, dataValue from source where id in ({IDS})Asset children query
select id from source where parentId={ID}Context capability
Events query
select id, name, type, occurred_at, modified_at, components, state, description, keywords from source where occurred_at > {AFTER} and occurred_at < {BEFORE}Event by id query
select id, name, type, occurred_at, modified_at, components, state, description, keywords from source where id = {ID}Event types query
select id, name, color, startstate, endstate, states, fields from source
Event type by id query
select id,name, color, startstate, endstate, states, fields from source where id = {ID}Fields query
select id, name, type, placeholder, options from source
Field by id query
select id, name, type, placeholder, options from source where id = {ID}Event fields linked to event query
select fieldId, value from source where eventId = {ID} Events by grouping key query
select id, name, type, occurred_at, modified_at, components, state, description, keywords, grouping_key from source where grouping_key = {GROUPINGKEY}