How to set up a Generic ODBC data source?
Generic ODBC provider is a Plant Integrations built-in provider, which enables access to historian repositories and databases via ODBC. All parameters used for connecting and retreiving data from the historian repositories, are stored in Plant Integration’s configuration database and can be defined either in ConfigHub or directly via Plant Integrations/database endpoints.
Largely, every configuration requires the following steps:
Establish a connection to the repository through the correct driver and connection string
Configure general parameters
Write and test the queries to extract data from the repositories
Concepts
Overview
Open Database Connectivity (ODBC) is a widely accepted application programming interface (API) for database access. It is based on the Call-Level Interface (CLI) specifications from Open Group and ISO/IEC for database APIs and uses Structured Query Language (SQL) as its database access language.
ODBC is designed for maximum interoperability - that is, the ability of a single application to access different database management systems (DBMSs) with the same source code. Database applications call functions in the ODBC interface, which are implemented in database-specific modules called drivers. The use of drivers isolates applications from database-specific calls in the same way that printer drivers isolate word-processing programs from printer-specific commands. Because drivers are loaded at runtime, a user only has to add a new driver to access a new DBMS; it is not necessary to recompile or relink the application.
Drivers
Drivers are libraries that implement the functions in the ODBC API. Each is specific to a particular DBMS; for example, a driver for Oracle cannot directly access data in an Informix DBMS. Drivers expose the capabilities of the underlying DBMSs; they are not required to implement capabilities not supported by the DBMS. For example, if the underlying DBMS does not support outer joins, then neither should the driver. The only major exception to this is that drivers for DBMSs that do not have stand-alone database engines, such as Xbase, must implement a database engine that at least supports a minimal amount of SQL.
Drivers need to be installed by the customers on the same server as Plant Integrations. If Plant Integrations is installed on the same server as the historian, chances are that the ODBC driver for the historian is already installed and available for Plant Integrations. You can configure user and system-wide ODBC connections using the “ODBC Data Sources” application in Windows.
Connection strings
The ODBC connection string typically has four/five major parts based on keywords: the driver, the server address, the database name, and a user name and password.
An ODBC connection string has the following syntax:
connection-string ::= empty-string[;] | attribute[;] | attribute; connection-string empty-string ::= attribute ::= attribute-keyword=attribute-value | DRIVER=[{]attribute-value[}] attribute-keyword ::= DSN | UID | PWD | driver-defined-attribute-keyword attribute-value ::= character-string driver-defined-attribute-keyword ::= identifierwhere
character-stringhas zero or more characters;identifierhas one or more characters;attribute-keywordis not case-sensitive;attribute-valuecan be case-sensitive; and the value of the DSN keyword does not consist only of blanks.
The Driver keyword names which driver ODBC is used for this connection, the DSN (Data Source Name) keyword names the data source, the UID and PWD keywords specify the user ID and password for the server.
Examples of Connection strings
SQL Server 2019
Standard security |
|
Connecting to a SQL Server instance |
|
Using a non-standard port |
|
Connect via an IP address |
NoticeDBMSSOCN=TCP/IP is how to use TCP/IP instead of Named Pipes. At the end of the Data Source is the port to use. 1433 is the default port for SQL Server |
Attach a database file on connect to a local SQL Server Express instance |
|
SQLite 3
Standard |
|
IP21
Standard |
|
Creating a Generic ODBC data source
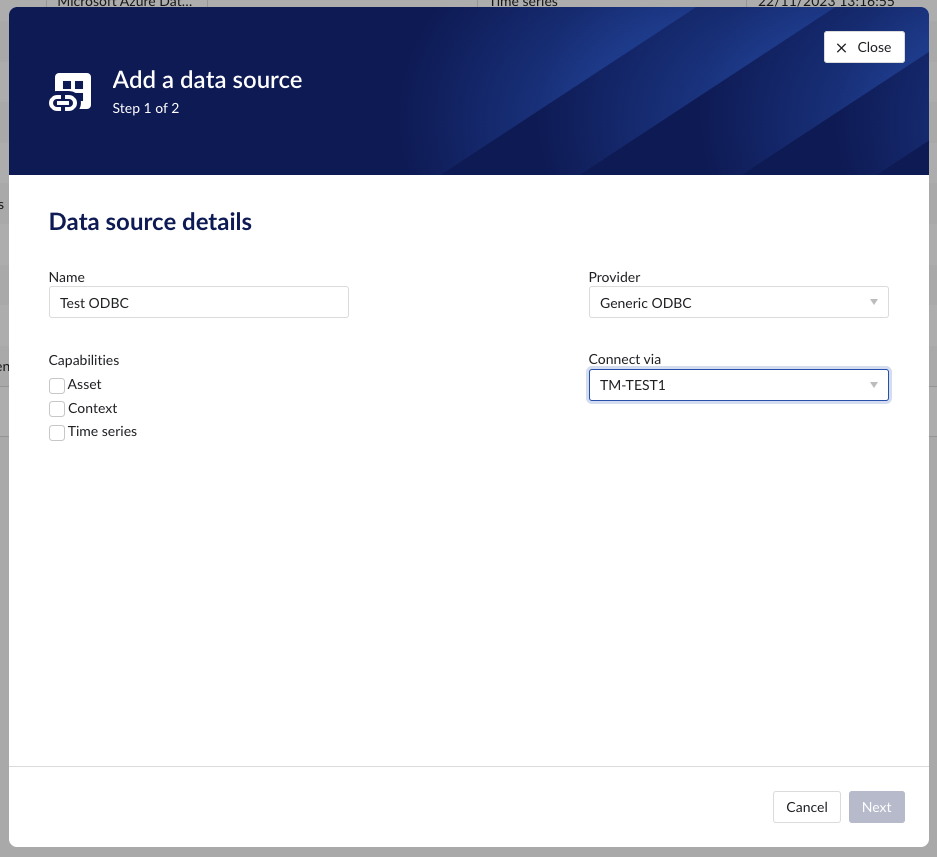
To integrate with and ingest data from a database that supports ODBC, a Data Source of provider type “Generic ODBC” can be added and configured in ConfigHub.
To do so, navigate to Data > Data Sources in the left side menu. Choose the "Add data source" option, which will open a wizard. In the first step, choose a name and select “Generic ODBC” from the Provider dropdown. This will add two new options to fill in:
Capabilities: tick the box for each capability you intend to activate
Connect via: which Plant Integrations you will use to connect to the database
Selecting the capabilities for the data source with the given checkboxes will define the additional steps in the wizard to complete, grouped in the following sections:
Connection details - Configure all properties related to the connection that will be established with the data source
Provider details - Configure properties that are shared by more than one capability
Time series details – Configure properties relevant to time series data
Asset details - Configure properties relevant to asset data
Context details - lists properties relevant to context data
Configuring Generic ODBC provider
Provider properties
The Generic ODBC provider uses provider properties to configure every aspect of the provider, this includes queries, credentials and date formats.
Property | Required | Capability | Remarks |
|---|---|---|---|
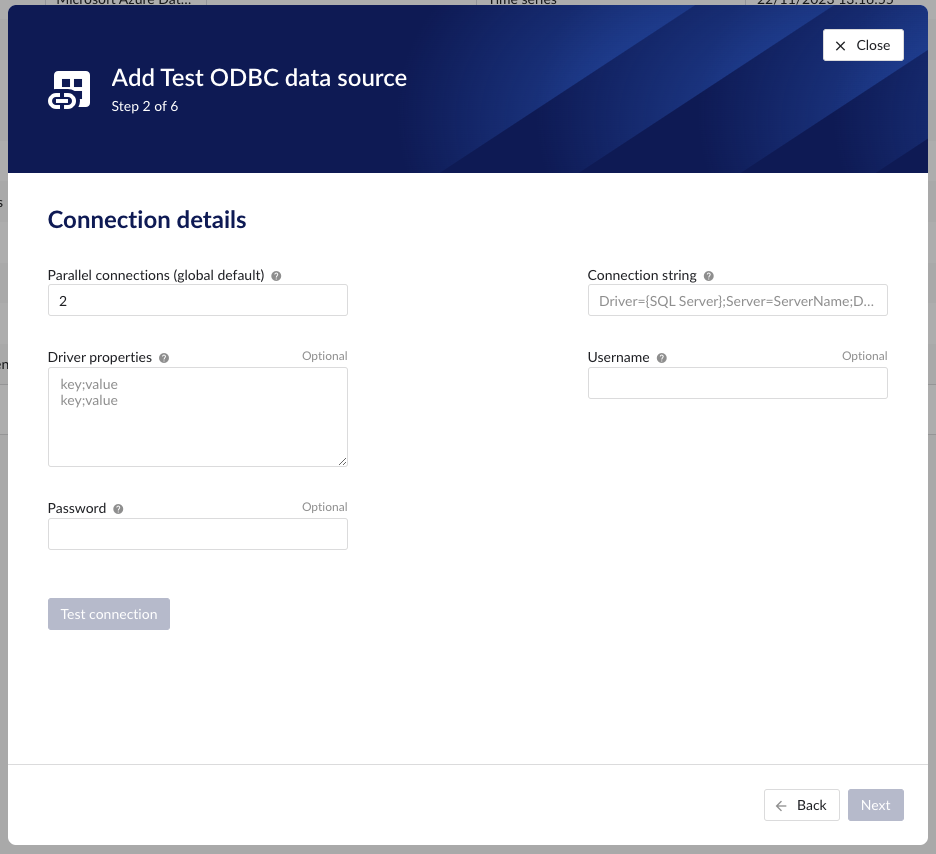
Connection string | yes | Time series Asset Event | Connection string used to connect to the underlying data source. When the same keywords are used in the connection string and the driver properties, the values from the driver properties are overwritten by the values from the connection string. Same logic applies for credentials : Username (UID) and passwords (PWD) from driver properties are overwritten by username and password from connection string and theses are overwritten by the username and password provider properties. NoticeAdvanced: When the Odbc driver does not support the UID or PWD keywords, but use Username and Password instead, you can specify these as dummy keywords in the driver properties and those will then be overwritten by the username and password provider properties specified in config hub. |
Driver properties | no | Time series Asset Event | Driver properties are used as an additional way to add keywords and their values to the connection string. Driver properties are seen as more general properties and will be overwritten by values specified in the connection string. |
Username | no | Time series Asset Event | A convenience field to enter the username used to establish a connection to the database. This information can also be specified in the connection string and driver properties. |
Password | no | Time series Asset Event | A convenience field to enter the password used to establish a connection to the database. This information can also be specified in the connection string and driver properties. WarningDriver properties and Connection string are not encrypted, password however is encrypted. |
Parallel connections | yes | Time series | Each data source has 2 queues: one interactive - plot calls, one non-interactive - index calls, batch calls etc. Parallel connections determine how many connections each queue has to the connector. By default there are 2 parallel connections to the connector. |
Property | Required | Capability | Remarks |
|---|---|---|---|
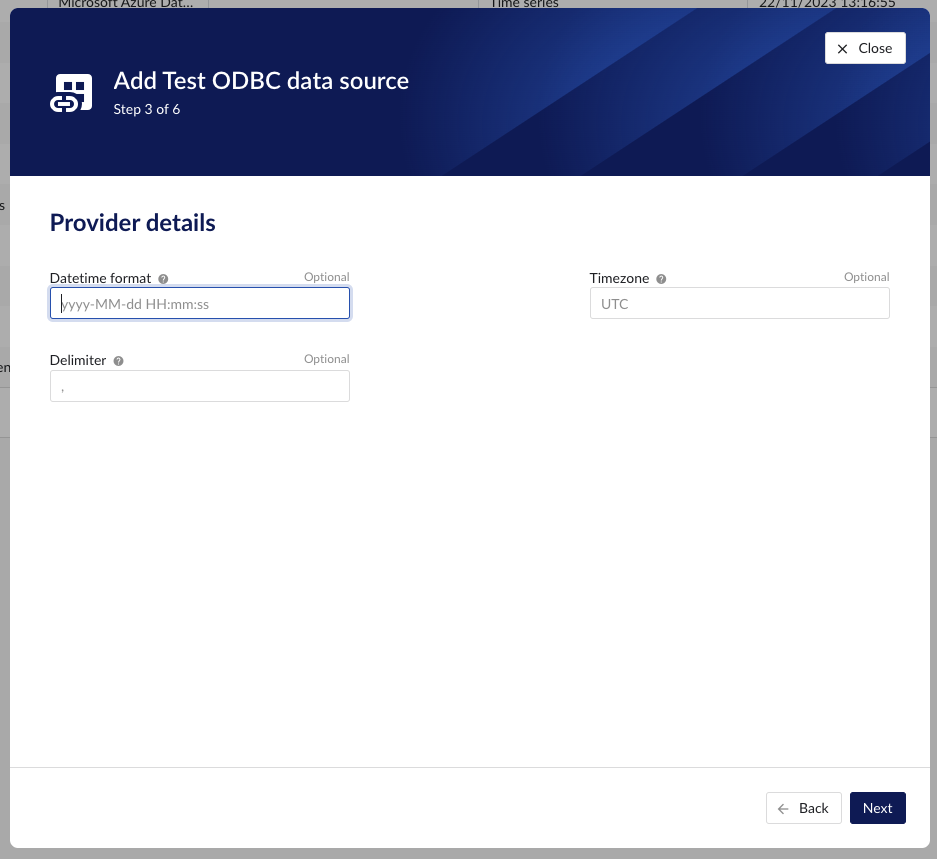
DateTime format | no | Time series Event | An optional format your time series data is stored in. The format should be expressed in .NET syntax: https://learn.microsoft.com/en-us/dotnet/standard/base-types/custom-date-and-time-format-strings |
Timezone | no | Time series Event | An optional timezone your time series data is stored in. Default is UTC. The list of supported values are defined by the operating system of Plant Integrations. To get this list you can use the following command: 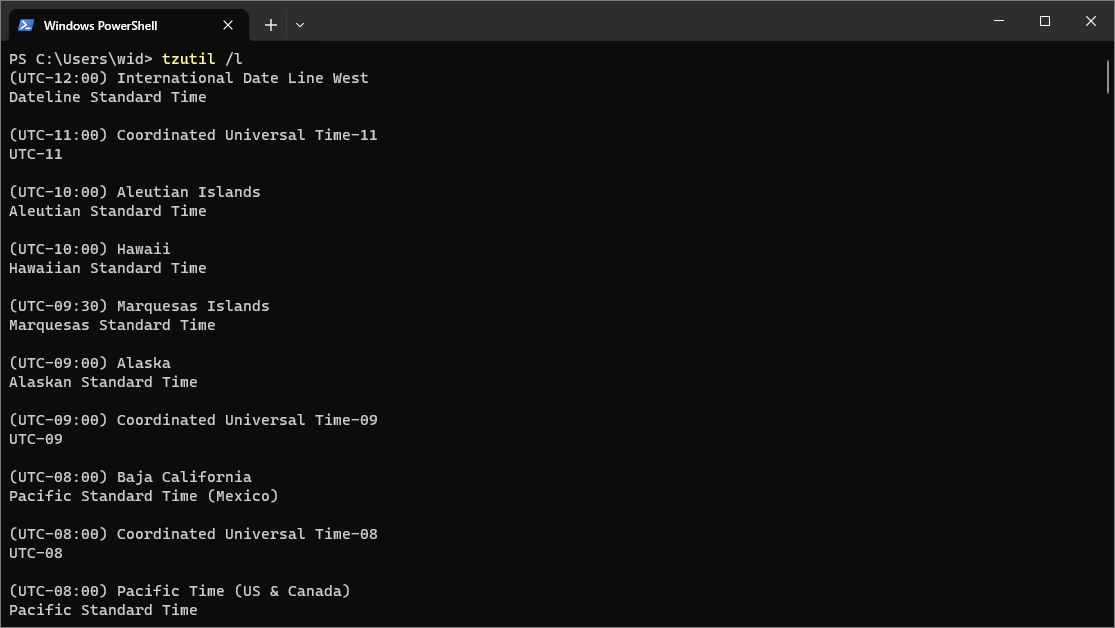 NoticeThe second line for each time zone is the identifier that can be used, e.g. “Pacific Standard Time“ |
Delimiter | no | Asset Event | Delimiter used to separate a multi string column/ field in the provider. The default is comma (,) Asset Capability
|
Property | Required | Remarks |
|---|---|---|
Tag list query | yes | A query used by TrendMiner to create tags. A query needs to be provided that will, given your database schema and tables. Example: select id, name, type, description, units from source Columns:
|
Index query | yes | A query used by TrendMiner to ingest time series data for a specific tag. The query is expected to return a ts (timestamp) and a value. ImportantThe results should be sorted ascending on timestamp, if not they will be sorted by the provider. Variables:
Example: select ts, value from source where id={ID} and ts>={STARTDATE} and ts<={ENDDATE} order by ts ascColumns:
|
Internal plotting | no | If this option is selected TrendMiner will use interpolation if needed to plot the tag on the chart on specific time ranges. If this value is not selected and no plot query is provided, TrendMiner will plot directly from the index. |
Plot query | no | A query used by TrendMiner to plot time series data for a specific tag. The query is expected to return a ts (timestamp) and a value. ImportantThe results should be sorted ascending on timestamp, if not they will be sorted by the provider. Variables:
Example: select ts, value from source where id={ID} and ts>={STARTDATE} and ts<={ENDDATE} order by ts ascColumns:
|
Digital state query | no | If tags of type DIGITAL are returned by the tag list query, TrendMiner will use this query to ask for the stringValue, intValue pairs for a specific tag to match a label with a number. Variables:
Example: select stringValue, intValue from source where id={ID}Columns:
|
Type mapping | no | If types differ from what TrendMiner uses and one wants to avoid to overcomplicate the query, a type mapping can be entered here. It can contain multiple lines and expect per line the value to be representing a custom type followed by a ; and a TrendMiner type. During the execution of the tag list query TrendMiner will then use this mapping to map the custom values returned in the query to TrendMiner tag types. customTypeA;ANALOG customTypeB;DIGITAL customTypeC;DISCRETE customTypeD;STRING |
Prefix | no | An optional text can be entered here that will be used to prefix the tag names in TrendMiner. WarningValue cannot be changed. |
Tag filter | no | An optional regular expression to be entered. Only tags with names that match this regex will be retained when creating tags (using the tag list query). |
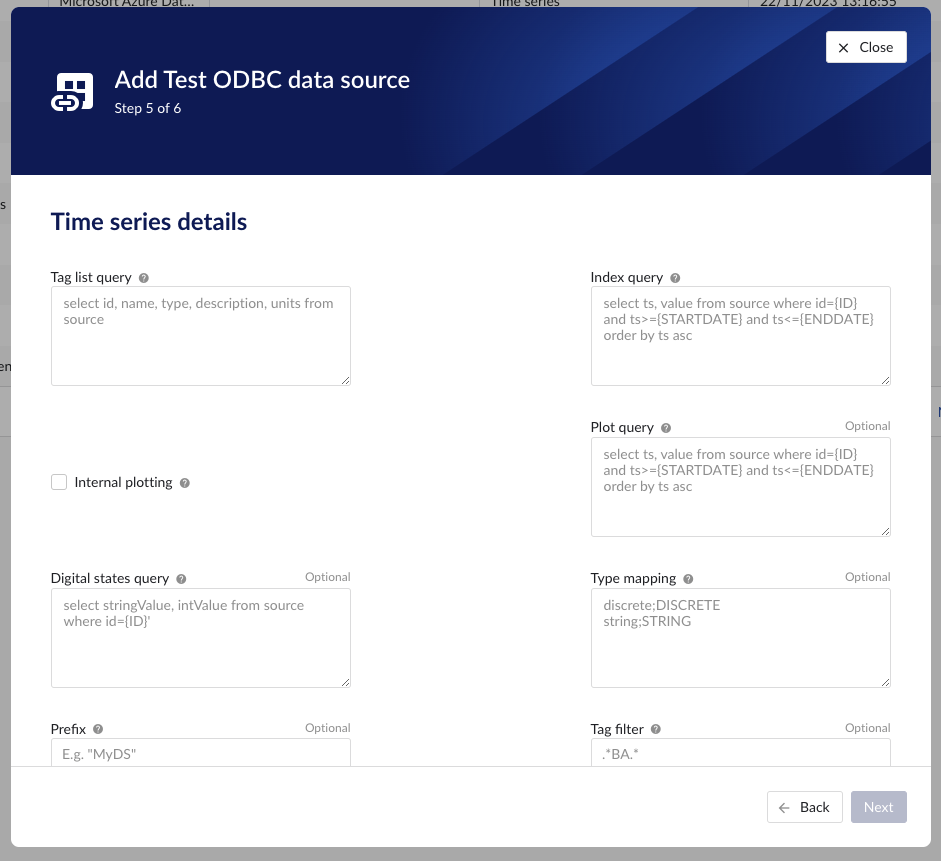
Property | Required | Remarks |
|---|---|---|
Root asset query | yes | This query needs to return details for a specific asset record. Example: select id, type, name, parentId, description, dataType, dataValue from source where parentId is NULL Columns:
|
Asset query | yes | This query is responsible for returning all top level elements from the asset tree structure. Variables:
Example: select id, type, name, parentId, description, dataType, dataValue from source where id in ({IDS})Columns:
|
Asset children query | yes | This query needs to return the ids of the direct descendants of this asset. Variables:
Example: select id from source where parentId={ID}Columns:
|
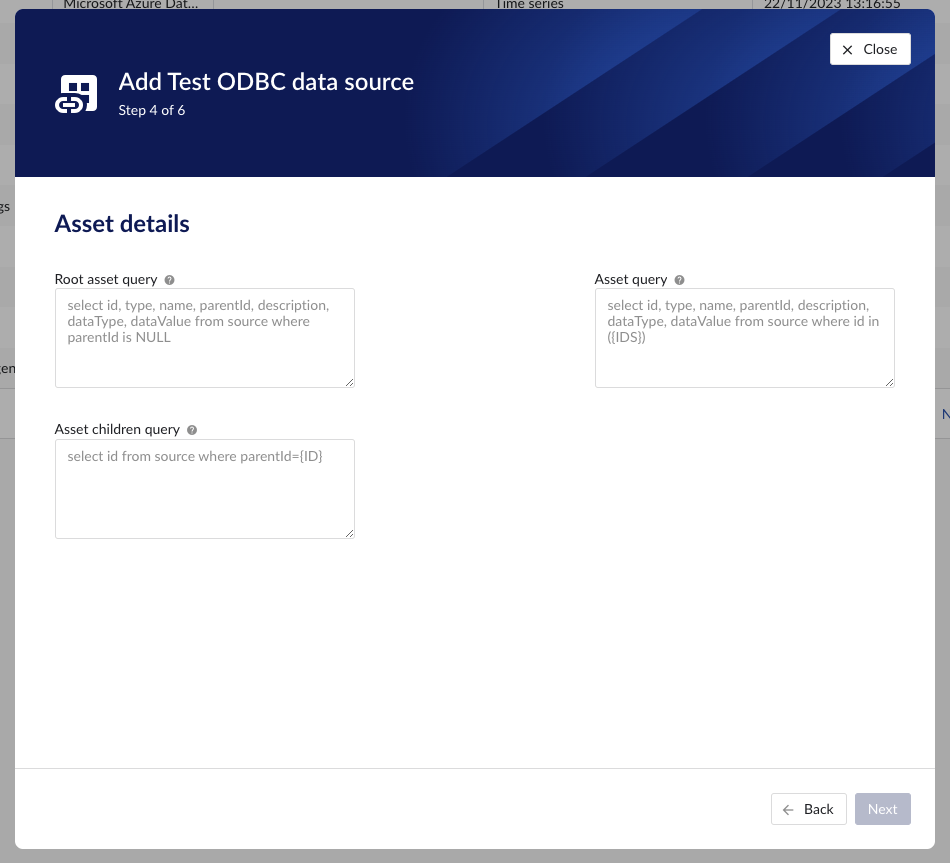
Property | Required | Remarks |
|---|---|---|
Events query | yes | This query is responsible for returning events from the source database. Context items will be generated based on these events. Variables:
Example: select id, name, type, occurred_at, modified_at, components, state, description, keywords, grouping_key from Event where occurred_at > {AFTER} and occurred_at < {BEFORE} and id > coalesce({CURSOR}, 0) limit {LIMIT}Columns:
|
Event by id query | yes | This query is responsible for returning a specific event from the source database. Variables:
Example: select id, name, type, occurred_at, modified_at, components, state, description, keywords, grouping_key from Event where Id = {ID}Columns:
|
Types query | yes | This query is responsible for returning a list of possible event types from the source database. Variables:
Example: select id, name, color, startstate, endstate, states, fields from eventtype where Id > coalesce({CURSOR}, 0) limit {LIMIT}Columns:
|
Type by id query | yes | This query is responsible for returning an event type from the source database. Variables:
Examples: select id, name, color, startstate, endstate, states, fields from Type where id = {ID}Columns:
|
Fields query | yes | This query is responsible for returning a list of possible custom fields from the source database. Variables:
Example: select id, name, type, placeholder, options from Field where Id > coalesce({CURSOR}, 0) limit {LIMIT}Columns:
|
Field by id query | yes | This query is responsible for returning a custom field from the source database. Variables:
Example: select id, name, type, placeholder, options from Field where Id = {ID}Columns:
|
Event fields query | yes | This query is responsible for returning custom field values for specific event. Variables:
Example: select fieldId, value from source where eventId = {ID}Columns:
|
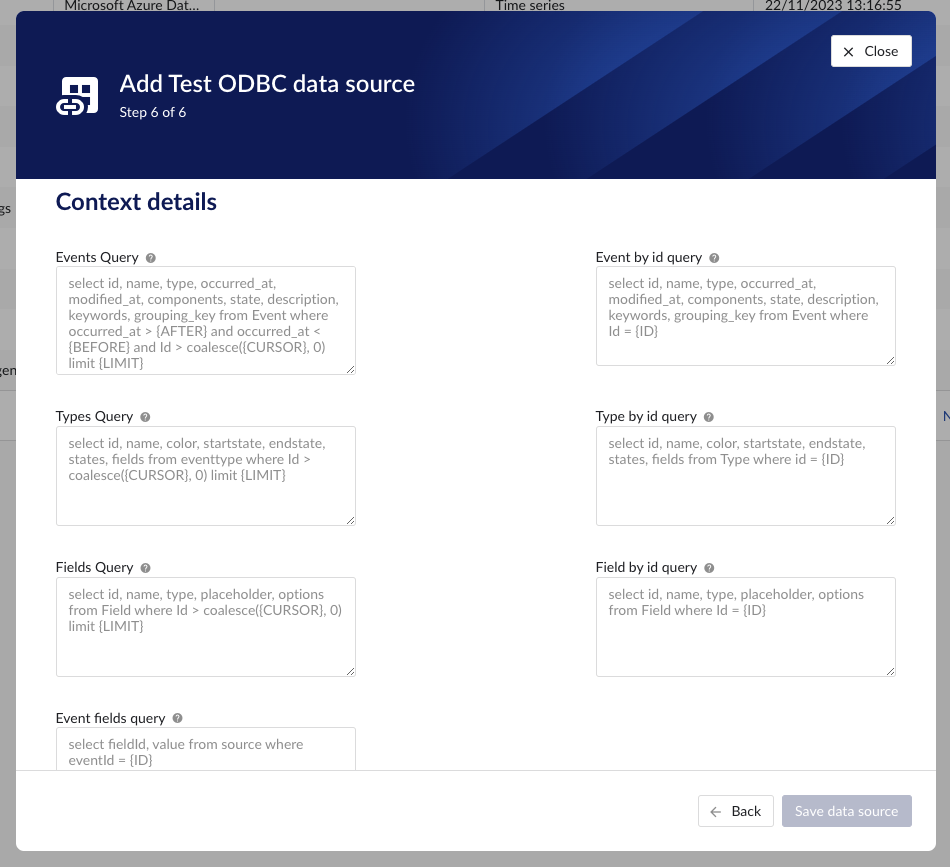
Example queries (Sqlite)
Below we provide some example queries that can be used in the Generic ODBC provider for the sqlite odbc drivers.
TIME SERIES CAPABILITY
Tag list query
select id, name, type, description, units from source
Index query
select ts, value from source where id={ID} and ts >= {STARTDATE} and ts <= {ENDDATE} order by ts ascPlot query
select ts, value from source where id={ID} and ts >= {STARTDATE} and ts <= {ENDDATE} order by ts ascselect ts, value from source where id={ID} and ts>={STARTDATE} and ts<={ENDDATE} order by ts ascDigital state query
select stringValue, intValue from source where id={ID}ASSET CAPABILITY
Root asset query
select id, type, name, parentId, description, dataType, dataValue from source where parentId is NULL
Asset query
select id, type, name, parentId, description, dataType, dataValue from source where id in ({IDS})Asset children query
select id from source where parentId={ID}EVENT CAPABILITY
Events query
select id, name, type, occurred_at, modified_at, components, state, description, keywords, grouping_key from Event where occurred_at > {AFTER} and occurred_at < {BEFORE} and id > coalesce({CURSOR}, 0) limit {LIMIT}Event by id query
select id, name, type, occurred_at, modified_at, components, state, description, keywords, grouping_key from Event where Id = {ID}Types query
select id, name, color, startstate, endstate, states, fields from eventtype where Id > coalesce({CURSOR}, 0) limit {LIMIT}Type by id query
select id, name, color, startstate, endstate, states, fields from Type where id = {ID}Fields query
select id, name, type, placeholder, options from Field where Id > coalesce({CURSOR}, 0) limit {LIMIT}Field by id query
select id, name, type, placeholder, options from Field where Id = {ID}Event fields query
select fieldId, value from source where eventId = {ID}