TrendMiner SaaS with a cloud-hosted data source
In this scenario, a secure connection needs to be established between the TrendMiner SaaS platform hosted in the cloud and data source(s), also hosted in the cloud.
Architecture schema
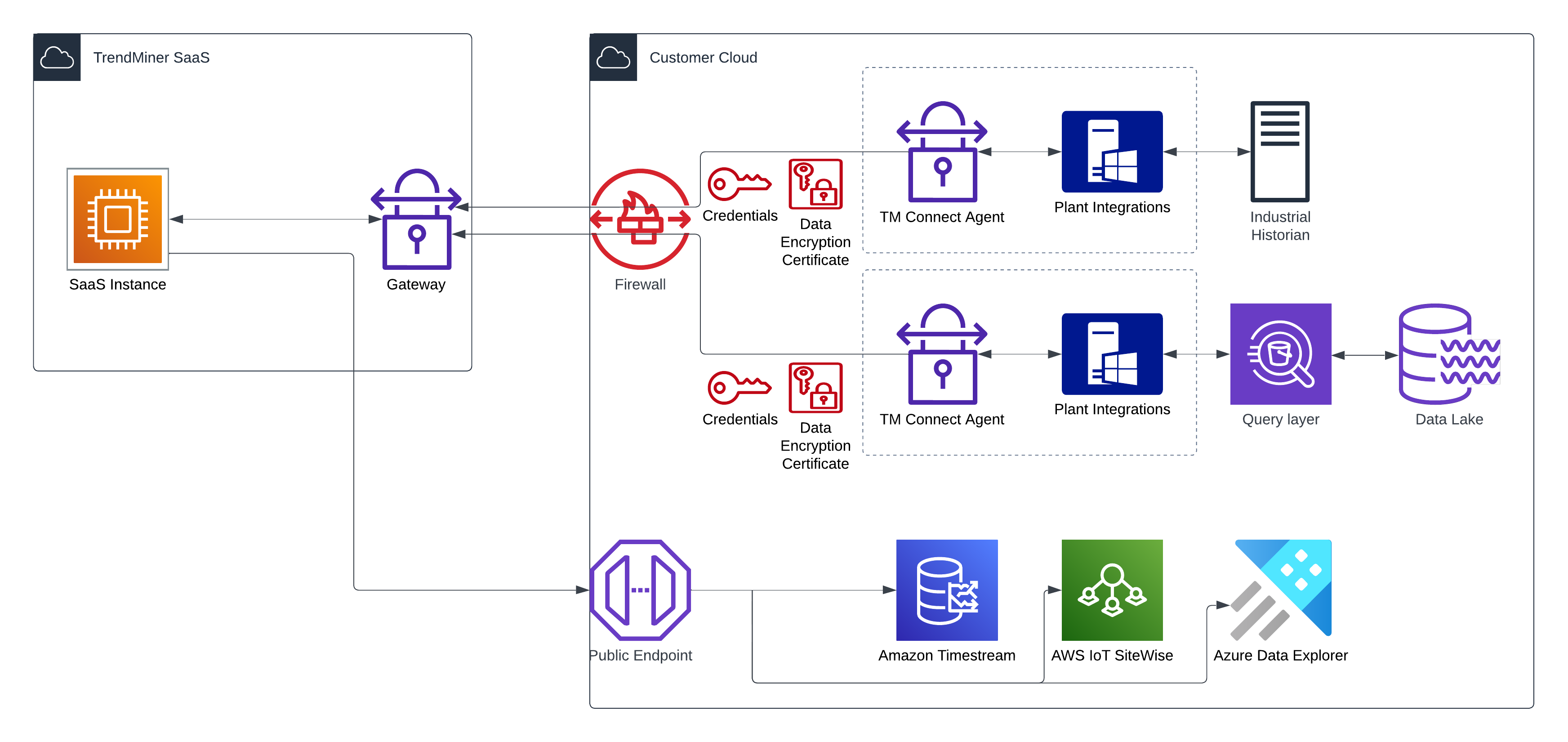
Example reference architecture for TrendMiner SaaS with a cloud data source
The need for the Plant Integrations module depends on the cloud data source. Many have a direct connection available that can be configured. For others, custom connections can be created. In this case, the Plant Integrations module needs to be installed on a Windows Server.
Strengths
Ability to outsource operations to the TrendMiner operations teams
Easily connect to your corporate data lake
Out-of-the-box connectors for cloud native data sources like AWS IoT SiteWise, Amazon Timestream, Microsoft Azure Data Explorer (Kusto ADX)
Considerations
Read performance is highly dependent on the architecture. Considerations are highly specific to the specific data lake or cloud data source. Some example considerations for Azure include:
Parquet gives much better performance than CSV files
Partitioning files time-based significantly improves performance if partitions are used in every query. The optimum between parquet file size and the number of partitions depends on the specific data and the frequency of data points in time series and needs to be investigated case by case.
It is recommended to look into Hot/Cool/Archive data storage to balance performance versus cost
Solutions exist to boost query performance. For example, Dremio improves query performance because it can build “reflections” on top of the data lake data. These are optimized data indices that can be cached in memory and provide huge boosts in query performance. Our advice is to look into a solution that supports this, especially for the more recent data (hours or days) to ensure that plotting requests and monitors on recent data get fast query responses.
Any tool that provides JDBC access can potentially be used, but performance might vary depending on the choice.
A delay in data ingestion in the cloud data source might cause a delay for monitors in TrendMiner. The ability of the query layer to support returning recent data is required. To achieve monitoring without significant delay, the development of a custom connector may be required.
Datasource connection
Data Lake:
The connection between the cloud data source and TrendMiner is usually done through a query layer. In general, this layer provides JDBC/ODBC connectivity and the ability to run queries (e.g. SQL or KQL) against the data source.
For generic or custom connections, the installation of the Plant Integrations module is required. This module exposes access to read data over a REST-based API (HTTP or HTTPS). TrendMiner only accesses this connector, not the data source directly.
The ingestion flow is outside of the scope of this reference architecture, as it is not important for TrendMiner how data arrives in the data lake, as long as it can be queried.
Cloud-native data sources:
Public Endpoint needs to be available in order to connect to such data sources as AWS IoT SiteWise, Amazon Timestream, Microsoft Azure Data Explorer (Kusto ADX). Connection will be established from TrendMiner SaaS Environment.