How to set up an Amazon Timestream data source?
The following sections will detail all the information needed for setting up an Amazon Timestream data source in TrendMiner.
To add an Amazon Timestream data source, in ConfigHub go to Data in the left side menu, then Data sources, choose + Add data source.
Type name of data source, select “Amazon Timestream” from the Provider dropdown. Selecting the capabilities for the data source with the given checkboxes will open additional properties to enter, grouped in following sections:
Connection details – lists properties related to the configuration of the connection that will be established with Amazon Timestream.
Time series configuration – lists properties relevant for the timeseries data.
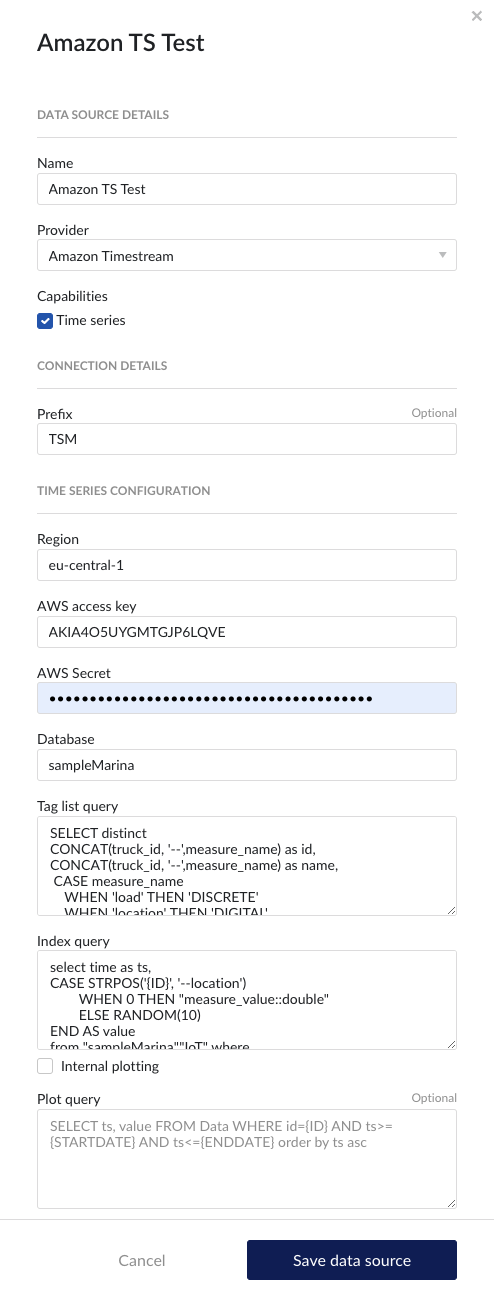
Following properties need to be populated to establish the connection:
“Prefix” - optional text can be entered here that will be used to prefix the tag names in TrendMiner, if a value is entered. Warning: this cannot be changed. The datasource can however be deleted and you can start the configuration over again.
"Region" – enter the availability zone region within AWS cloud in which the Amazon Timestream instance is configured. For more information, please consult the AWS Documentation.
"AWS access key" – enter the access key to authenticate. This is the access key id as created in AWS IAM. For more information, please consult the AWS Documentation.
"AWS Secret" – enter the secret to authenticate. This is the AWS secret as created in AWS IAM. For more information, please consult the AWS Documentation.
“Database” – enter the name of database in Amazon Timestream. This is primarily used to test the connection liveness from TrendMiner to Amazon Timestream.
“Tag list query” - a query used by TrendMiner to create tags. A query needs to be provided that given the database schema and tables used will return the following columns:
id - this is mandatory and must have a unique value for each row returned by the query.
name - this is mandatory and must have a value.
type - an optional type indication. If the type column is not in the query, TrendMiner will use the default type which is ANALOG. Custom types can be returned here not known to TrendMiner but then a type mapping must be added as well. See also type mapping below. Without additional type mapping it must be one of the following TrendMiner tag types: ANALOG, DIGITAL, DISCRETE, STRING
description - an optional description to describe the tag. Can return an empty value or null.
units - an optional indication of the units of measurement for this tag. Can return an empty value or null.
The order of the columns in the query needs to be: id, name, type, description, units
“Index query” - a query used by TrendMiner to ingest timeseries data for a specific tag. The query is expected to return a ts (timestamp) and a value. The following variables are available to be used in the WHERE clause of this query. The variables will be substituted at query execution with values. There should not be any NULL values returned by the SELECT statement so including "IS NOT NULL" in the WHERE clause is strongly recommended.
{ID}. The id as returned by the tag list query.
{STARTDATE} TrendMiner will ingest data per intervals of time. This denotes the start of such an interval.
{ENDDATE} TrendMiner will ingest data per intervals of time. This denotes the end of such an interval.
{INTERPOLATION}: Interpolation type of a tag, which can be one of two values: LINEAR or STEPPED.
{INDEXRESOLUTION}: Index resolution in seconds. It can be used to optimise a query to return the expected number of points.
“Digital states query” - if tags of type DIGITAL are returned by the tag list query, TrendMiner will use this query to ask for the {stringValue, intValue} pairs for a specific tag to match a label with a number. The query expects to return a stringValue and an intValue and can make use of the {ID} variable in the where clause. The variable will be substituted at query execution with a value.
“Tag filter” - an optional regular expression to be entered. Only tags with names that match this regex will be retained when creating tags (using the tag list query).
“Type mapping” - if types differ from what TrendMiner uses and one wants to avoid overcomplicating the query, a type mapping can be entered here. It can contain multiple lines and expect per line the value to be representing a custom type followed by a ; and a TrendMiner type. During the execution of the tag list query TrendMiner will then use this mapping to map the custom values returned in the query to TrendMiner tag types.
customTypeA;ANALOG
customTypeB;DIGITAL
customTypeC;DISCRETE
customTypeD;STRING
Example queries
The following exemplary queries are based on the sample data setup in Amazon Timestream – containing a sample database with IoT sample data. Amazon Timestream will then create a sample database that contains IoT sensor data from one or more truck fleets to streamline fleet management and to identify cost optimization opportunities such as reduction in fuel consumption. For more information, please consult https://docs.aws.amazon.com/index.html.
Tag list query
This query treats the location measurements as tags of type STRING.
SELECT distinct
CONCAT(truck_id, '--',measure_name) as id,
CONCAT(truck_id, '--',measure_name) as name,
CASE measure_name
WHEN 'load' THEN 'DISCRETE'
WHEN 'location' THEN 'STRING'
ELSE 'ANALOG'
END
AS type,
CONCAT(make, ' ', model, ' (', fleet , ')') AS description,
CASE measure_name
WHEN 'load' THEN 'kg'
WHEN 'speed' THEN 'km/h'
WHEN 'fuel-reading' THEN '%'
ELSE ''
END
AS unit
FROM sampleDB2.IoTAlternative query treats the location measurements as tags of type DIGITAL. This is a somewhat less realistic case, but it serves the purpose of also demonstrating tags of type DIGITAL. Location measurements are given a random number between 1 and 10 in the matching alternative index query.
SELECT distinct
CONCAT(truck_id, '--',measure_name) as id,
CONCAT(truck_id, '--',measure_name) as name,
CASE measure_name
WHEN 'load' THEN 'DISCRETE'
WHEN 'location' THEN 'DIGITAL'
ELSE 'ANALOG'
END
AS type,
CONCAT(make, ' ', model, ' (', fleet , ')') AS description,
CASE measure_name
WHEN 'load' THEN 'kg'
WHEN 'speed' THEN 'km/h'
WHEN 'fuel-reading' THEN '%'
ELSE ''
END
AS unit
FROM sampleDB2.IoT Index query
select time as ts,
CASE WHEN measure_value::double is not null
THEN cast(measure_value::double as varchar)
ELSE measure_value::varchar
END AS value
from "sampleDB2"."IoT" where
concat(truck_id, '--',measure_name) = '{ID}'
and time >= '{STARTDATE}'
and time <= '{ENDDATE}'
order by time ascAlternative index query for digital location tags. Where we for the purpose of this demo case assign a random number to a location value for a timestamp.
select time as ts,
CASE SPLIT('{ID}', '--')[2]
WHEN 'location' THEN RANDOM(10)
ELSE "measure_value::double"
END AS value
from "sampleDB2"."IoT" where
concat(truck_id, '--',measure_name) = '{ID}'
and time >= '{STARTDATE}'
and time <= '{ENDDATE}'
order by time ascDigital states query
This query is applicable when the alternative tag list and alternative index query is used.
SELECT 'STATE0' as stringValue, 0 as intValue UNION SELECT 'STATE1', 1 UNION SELECT 'STATE2', 2 UNION SELECT 'STATE3', 3 UNION SELECT 'STATE4', 4 UNION SELECT 'STATE5', 5 UNION SELECT 'STATE6', 6 UNION SELECT 'STATE7', 7 UNION SELECT 'STATE8', 8 UNION SELECT 'STATE9', 9 UNION SELECT 'STATE10', 10 ORDER BY 1